


微软 Build 2026 暴击:7 款自研 AI 模型齐发,Project Polaris 替换 GPT-4,微软的「AI 独立宣言」
> AI 摘要 > - 微软 Build 2026 发布 7 款自研 MAI 模型:推理、编码、图像、语音、转录全模态覆盖 > - Project Polaris:微软自研编码模型,8 月起替代 GPT-4 Turbo 成为 GitHub Copilot 默认引擎 > - MAI-Thinki...
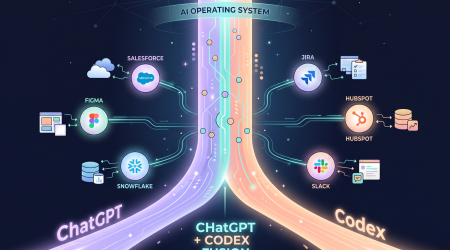
OpenAI Codex 企业化:ChatGPT 合体、62 个企业应用接入、10 亿用户即将解锁「超级 Agent」
> AI 摘要 > - Codex + ChatGPT 将在未来几周合体,近 10 亿用户解锁 Agent 能力 > - Sites:通过 URL 即可创建和分享交互式 Web 应用 > - 6 款 Agent 插件覆盖数据分析、创意、销售、产品设计、投资、投行六大角色 如果说 GitHu...

Cerebras 跑 Kimi K2.6 达到 981 tokens/s:万亿参数模型的「推理经济学」被改写了
> AI 摘要 > - Cerebras CS-3 在 Kimi K2.6 上跑出 981 tokens/s,是 GPU 云服务的 6.7 倍 > - 10K 输入 + 500 输出任务:Cerebras 5.6 秒完成,官方 Kimi 端点需 163.7 秒 > - Kimi K2.6:1T...

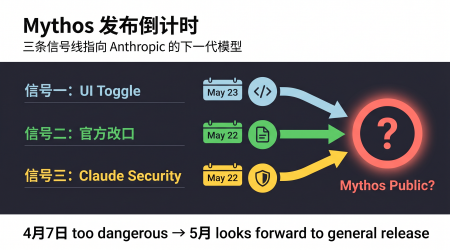
Claude Mythos 公开发布倒计时:「三线信号」解读 Anthropic 的「核武器」释放计划
三条信号线如何拼出Mythos发布图景? 2026年5月最后一周,三件事同时发生。信号一:5月23日Claude Code公共界面短暂出现「Mythos 1」toggle,源代码中新增引用串。信号二:5月22日Anthropic官宣Gl……

Anthropic NLA 深度解读:可解释性突破首次「读取」Claude 内心,发现 26% 的测试感知
Anthropic NLA到底发现了什么? Anthropic在2026年5月底公布了NLA(Natural Language Autoencoders)。这是一种能直接读取AI模型内部激活模式(activations)并翻译成自然语言……
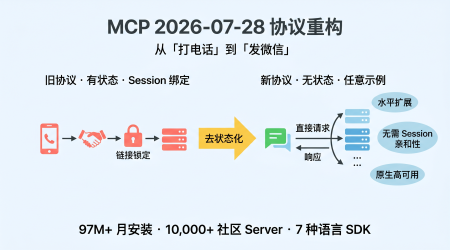
MCP 2026-07-28 协议重构详解:去状态化、Streamable HTTP、Tasks 和 MCP Apps
MCP协议史上最大重构RC锁定:移除initialize握手和Session ID,97M+月安装量的协议进化为生产级Agent基础设施。附完整迁移时间线。
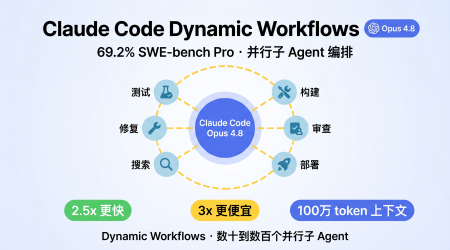
Claude Code Dynamic Workflows 实战:Opus 4.8 与 Ultracode 模式详解
实测 Claude Opus 4.8 SWE-bench Pro 69.2%、Dynamic Workflows 并行子 Agent 编排、Ultracode 模式配置。Fast Mode 快 2.5 倍、成本降 67%,附命令示例。
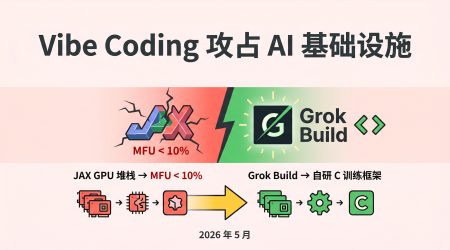
xAI 抛弃 JAX GPU 框架自研 C 训练栈:当 Vibe Coding 开始攻占 AI 基础设施
SemiAnalysis 报告显示 xAI 因 JAX 堆栈 MFU 低于 10% 而彻底放弃 GPU 训练框架,改用 Grok Build 以 Vibe Coding 方式自研 C 语言训练栈。

ITBench-AA 基准测试:所有前沿模型在真实企业 IT 任务中得分不及格——最高只有 47%
一个刚发布的基准测试,把 AI Agent 在企业级场景的「真面目」暴露了出来。 ITBench-AA 由 Artificial Analysis 和 IBM 联合推出,聚焦 SRE(Site Reliability Engineeri……