


微软 Build 2026 暴击:7 款自研 AI 模型齐发,Project Polaris 替换 GPT-4,微软的「AI 独立宣言」
> AI 摘要 > - 微软 Build 2026 发布 7 款自研 MAI 模型:推理、编码、图像、语音、转录全模态覆盖 > - Project Polaris:微软自研编码模型,8 月起替代 GPT-4 Turbo 成为 GitHub Copilot 默认引擎 > - MAI-Thinki...
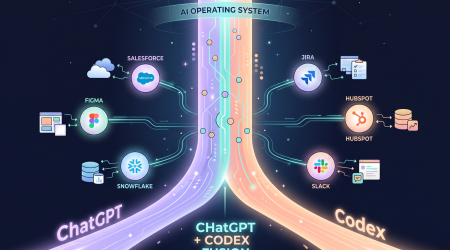
OpenAI Codex 企业化:ChatGPT 合体、62 个企业应用接入、10 亿用户即将解锁「超级 Agent」
> AI 摘要 > - Codex + ChatGPT 将在未来几周合体,近 10 亿用户解锁 Agent 能力 > - Sites:通过 URL 即可创建和分享交互式 Web 应用 > - 6 款 Agent 插件覆盖数据分析、创意、销售、产品设计、投资、投行六大角色 如果说 GitHu...

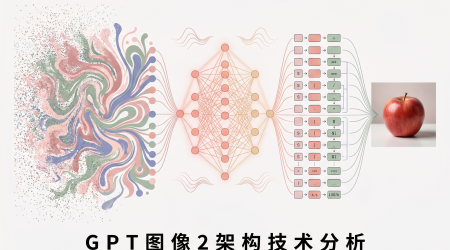
GPT Image 2 技术内核拆解:三层架构如何实现文字渲染和布局突破
这不是 DALL-E 4 - - 这是一场彻头彻尾的架构革命 2026 年 4 月 21 日,OpenAI 发布了 GPT Image 2。同一天,宣布 DALL-E 2 和 DALL-E 3 将于 5 月 12 日退役。这不是升级,这是换血。 如果你用过第一代 GPT Image(20...

MCP 的三个「第一次」:OpenAI 企业级安全连接、Runway 视频生成接入、Perplexity 分词器开源
Model Context Protocol(MCP)是 Anthropic 在 2024 年底推出的开放协议,用于让 AI 模型连接外部工具和数据源。推出时大多数人的反应是「又一个协议」。 一年半后的今天,MCP 的生态已经发生了根本变化。而 2026 年 5 月 27 日,可能是 MCP 历史上最重要的一天——三个「第一次」在同一天完成。 1. 第一次企业级安全连接 OpenAI 发布了一个看似简单的功能——「私人 MCP 服务器的安全连接」——但细节决定了它的意义: 「你的团队保持 MCP 服务器在你的网络内,ChatGPT、Codex 和 Responses API 通过仅出站 HTTPS 连接。」 这句话的关键词是「仅出站」(outbound-only)。 传统上,企业将内部服务暴露给外部 AI 厂商需要做隧道、VPN、甚至是防火墙规则修改。安全团队最怕的就是在防火墙上开新的入站端口。OpenAI 的方案绕过了整个问题:Agent 主动用 HTTPS 连接 MCP 服务器,不需要企业接受任何入站流量。 这背后是一个行业趋势:MCP 正在从 Claude...

FastVideo Dreamverse 开源:一张 B200,7 秒生成 30 秒高清视频
实时视频生成又多了一个开源选项。Sky Computing Lab 在 5 月 27 日开源了 FastVideo Dreamverse——基于单张 NVIDIA B200 GPU 和 LTX-2 模型,实现实时视频生成的氛围引导工具。核心数字:7 秒生成 30 秒 1080p 视频。 来源:X: @haoailab / GitHub / Blog 为什么重要 实时视频生成有三个关键门槛:速度(不能等几分钟)、质量(1080p 是底线)、硬件成本(能不能跑在单卡上)。FastVideo Dreamverse 三个都过了。 对比一下同一天 Runway 发布的 MCP 服务器——Runway 走的是云端 API 路线,FastVideo 走的是本地开源路线。前者方便但花钱,后者需要硬件但免费。 技术栈 GPU:NVIDIA...

Cursor Composer 2.5 实测:一个 Kimi K2.5 微调模型,凭什么在代码基准上对标 Opus 4.7——价格只要 1/60
5 月 18 日,Cursor 发了 Composer 2.5。
没有发布会,没有博客预告。一个周日下午,版本号悄悄跳了。社区开始跑分,然后数据出来了:SWE-bench Multilingual 79.8%,比 Composer 2 高了 6 个百分点。CursorBench 默认模式下 63.2%,超过 Opus 4.7 的 61.6%。但真正让开发者社区讨论的不是分数——是价格。
Standard 模式下,每任务成本 $0.07。Opus 4.7 max 是 $4.10。差了将近 60 倍。
Key Takeaways
– Composer 2.5 SWE-bench 79.8% 对标 Opus 4.7 的 80.5%,CursorBench 默认模式 63.2%...

Claude Managed Agents 三大新能力详解:Dreaming、Outcomes 和多代理编排,Agent 不再只是「接个 API」
5 月 6 日,Anthropic 在旧金山举办了第二届 Code with Claude 开发者大会。和去年发布新模型不同,今年他们没有发任何新模型——而是发了一套 Agent 基础设施。
Claude Code 的创作者 Boris Churnney 在台上说了一句话:”Anthropic 内部已经没有手写代码了。“与其说这是炫耀,不如说是一个信号:当一家 AI 公司自己的开发流程已经完全由 Agent 驱动,他们要解决的下一个问题就不是「模型够不够强」,而是「Agent 能不能稳定跑在生产环境里」。
这就是 Code with Claude 2026 的主题。Anthropic 为 Claude Managed Agents 发布了三个核心能力——Dreaming(跨会话记忆)、Outcomes(评分驱动的质量循环)、Multi-Agent Orchestration(多代理并行编排)——外加 Claude Finance 和 Add-ins...
8.5k Star、699 Fork、Product Hunt #3:OpenHuman 这款 AI Agent 平台为什么突然爆了?
2026年5月第二周,GitHub Trending 榜上换了个新面孔。不是新的编程框架,不是新的 LLM 推理引擎,而是一个叫 OpenHuman 的桌面 AI Agent——17,709 Star,1,547 Fork,60个贡献者,v0.53.43 版本每几天迭代一次。 它在 Product Hunt 上冲到 #3,Dev Community 上多篇文章同时讨论。Tech Times 写了一篇尖锐的分析:《The Agent That Reads You First》。 但这个项目的有趣之处不在于增长数字——而是在于它选择了一条和所有主流 AI Agent 都不同的技术路线。它不是「等你描述任务然后执行」,而是「在你开口之前,它已经通过你的 Gmail、GitHub、Notion、Slack、Calendar 建立了一张上下文地图」。 Key Takeaways– OpenHuman 以「上下文优先」路线切入,区别于 OpenClaw 的广度模式和 Hermes 的观察学习模式– 118+ 第三方 OAuth...

别再说AI视频不专业了,原生4K、角色一致性和每周15亿张图改变了局面
先说一个数字:ChatGPT每周有超过15亿张图片被生成。不是1500万,是15亿。OpenAI官方5月19日披露了这个数据,距离他们发布Images 2.0才几个月时间。 这件事放在一年前,谁也想不到。但现在回头看,AI图像和视频生成正在同时经历一场质变——画质更好了,角色不乱变了,工具也从”玩玩而已”变成了”真能干活的”。我们不谈虚的,就聊三件刚发生的事。 Kling AI拿出了原生4K,好莱坞先开始用了 5月20日,Kling AI正式推出了全球首个原生4K视频生成模型。关键词是”原生”——不是拍个低分辨率视频再拉大,而是从底层就开始渲4K画质。目前已获得好莱坞制片人、动画工作室Wonder Studios和动画导演的三方采用反馈,共同指向:AI视频生成开始满足专业制作的质量底线了。 角色一致性:PixVerse发现了一个简单但被忽略的解法 5月20日,PixVerse团队展示了一个工作流:在角色开始运动之前,先用AI生成一张清晰的角色分镜图作为参考,然后再基于这个分镜生成视频。这个看似简单的”多一步”操作,恰恰解决了AI视频最让人头疼的问题:同一个角色在不同镜头里长得不一样。用他们的话说:”相同的角色、清晰的故事节点、镜头指导、动作细节——一致性始于动作之前。” 每周15亿张图:ChatGPT正在成为最大的图像生成平台 ChatGPT周生成15亿张图意味着什么?做个不严谨的参照:Statista数据显示2023年全球数码相机出货量约780万台。按此估算,ChatGPT一周生成的图像数量大约相当于全球数码相机全年销量的2倍。这个趋势对AI视频生成有直接影响——图像生成的”人人都能玩”正在培养一批对AI视觉内容不抗拒的用户。 FAQ AI视频生成现在是免费的吗? Kling AI和PixVerse都提供免费试用额度,但4K原生生成通常需要付费订阅。新用户注册一般有免费生成次数。 原生4K和普通视频有什么区别? 原生4K是模型从底层直接渲染3840×2160分辨率,每个像素都是AI计算出来的。普通方式是先生成720p/1080p再放大,放大过程会导致画面模糊或角色变形。 我一个普通人能做出来专业级视频吗? 可以,但不等于”随便点一下就行”。好的AI视频需要写清楚提示词,PixVerse展示的例子说明:细节越具体,效果越好。多试几次就能摸到门道。 数据来源:OpenAI/X (@OpenAI)、PixVerse/X (@PixVerse_)、Kling AI/X (@Kling_ai),2026年5月🔗 相关阅读: