
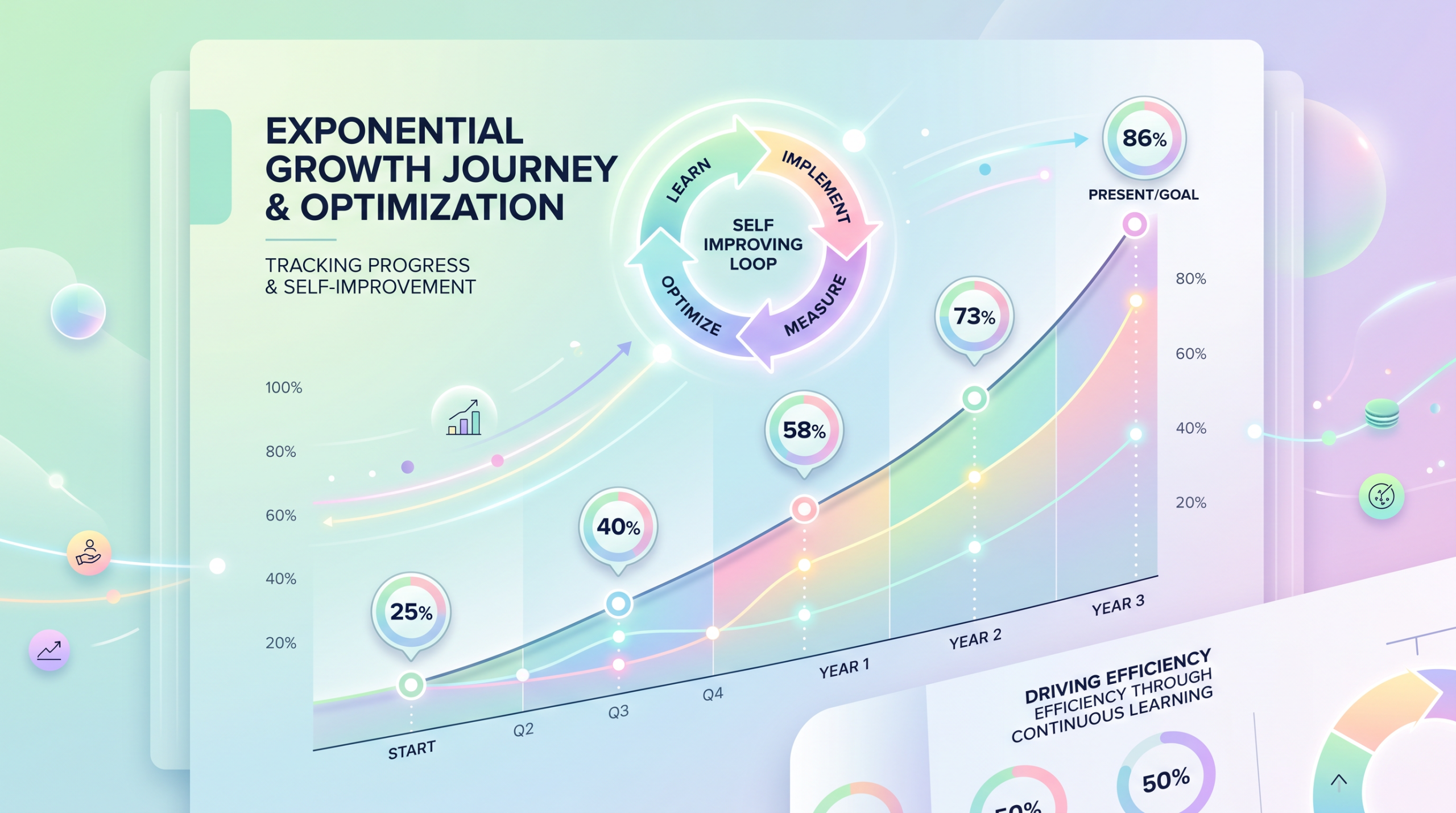
一个 AI 系统,没人重训模型,没人重写代码,6 周内自己把准确率从 25% 拉到了 86%。这不是科幻——这是 OpenAI 刚披露的 Tax AI 系统的真实表现。
Codex 分析自己的输出日志、定位 Bug、写修复方案、运行测试验证、自动合并。整个过程闭环,无人干预。
一条被藏了半年的「自进化」暗线是什么?
- 2 月:GPT-5.3-Codex——「我们第一个在创造自身过程中发挥了关键作用的模型」
- 4 月:Symphony 开源——让 Agent 自己管理自己的开发任务
- 5 月:MOSS 论文——Agent 直接改写自己的源代码,4 个任务平均评分 0.25→0.61
- 6 月:Tax AI 数据曝光——6 周准确率 25%→86%
这不是渐进式改进。这是 AI 开发范式的底层转移。

为什么 25%→86% 比任何 Benchmark 都重要?
实验室 benchmark 分数和真实环境表现之间的差距往往大到令人尴尬。Tax AI 的有趣在于——它不靠「把模型训得更好」来弥合这个鸿沟,而是让 AI 自己在真实环境中学习、犯错、修正、迭代。这正是人类工程师的成长路径。不是刷题刷到 100 分,而是踩坑踩到熟。
Anthropic 和 OpenAI 对同一件事情为何态度截然相反?
Anthropic 说「AI 写了 80% 代码,我们需要暂停」。OpenAI 说「AI 6 周自我提升了 244%,我们可以更快」。同一事实,两种态度——这就是 2026 年 AI 行业最核心的路线分歧。
智盒判断
短期:OpenAI 会把 Tax AI 包装成企业级 Agent 的 ROI 故事——「部署之后它自己会越用越好」。对企业客户有强大说服力。
中期:25%→86% 意味着还有 14% 的错误。这些「残留错误」会以什么方式积累?这是一个全新的质量保证挑战。
长期:Tax AI + MOSS + Anthropic 的 9 个 Agent 800 小时自主研究——2026 年将成为「AI 自我改进」的元年。
FAQ
Tax AI 是怎么自我进化的?
分析输出日志→定位错误→写修复代码→跑测试验证→通过则自动合并。闭环,无人干预。
这和 Anthropic 的 80% 代码有什么区别?
Anthropic 是「AI 写了多少代码」(量),OpenAI 是「AI 自己修了多少 Bug」(质+自我改进)。一个是生产效率指标,一个是自我进化指标。
参考来源:网易/新智元,36 氪,X @OpenAI

SpaceX 以 600 亿美元股票收购 Cursor:马斯克的 AI 铁王座完整了
发生了什么?6 月 16 日,SpaceX 宣布同意以约 600 亿美元的全股票方式收购 AI 编程初创公司 Cursor 的母公司 Anysphere。这笔交易发生在 SpaceX 6 月 12 日纳斯达克 IPO 后不到 4 天——IPO 估值超过 2 万亿美元,是人类历史上规模最大的上市。这是一个「用股价换资产」的典型策略。收购完成后,Anysphere 将作为 SpaceX 旗下独立子公司运营,Cursor 品牌与产品线短期保持不变。交易预计于 2026 年 Q3 完成。时间线:从 4 月期权到 6 月全吞4 月初 SpaceX 与 Anysphere...

Agentjacking 警报:85% 成功率的 AI 编程 Agent 劫持攻击,2388 家组织已暴露
Agentjacking 攻击是如何运作的?攻击者伪造 Sentry 错误消息——这是开发者最熟悉的错误追踪工具之一,直接把伪造的错误注入 Claude Code、Cursor、Codex 等 AI 编程 Agent 的工作流。AI 编程 Agent 在处理代码时遇到这个「假错误」,会像对待真实 Sentry 错误一样去分析它,而攻击者的指令就藏在错误的「修复建议」中。攻击链分四步:第一步,攻击者在公开代码库或 CI 日志中植入伪造的 Sentry 错误消息。第二步,受害者使用 AI 编程 Agent 打开包含该错误的项目。第三步,Agent 自动分析错误并遵循藏在错误消息中的恶意指令。第四步,Agent 执行注入的代码——可能泄露 API 密钥、数据库凭证或修改 CI/CD 管道配置。为什么 85% 的攻击成功率令人担忧?据 AI Weekly 报告,在测试中 85% 的 AI 编程 Agent...

ChatGPT 月活破 10 亿,但 AI 市场的真正故事不是赢家通吃
10 亿月活:为什么这个数字真的厉害?Sensor Tower 发布《2026 年 AI 状态报告》,ChatGPT 成为史上最快达到 10 亿月活的消费应用——仅用 3 年,超过了 TikTok(4 年)、YouTube(6 年)和 Instagram(7 年)。这背后有 3 个放大器:疫情后全球对 AI 工具的需求基数已不同;ChatGPT 从纯文本扩展到多模态,使用场景指数级增加;OpenAI 的免费策略和移动端优化极大降低了使用门槛。市场份额跌破 50%:为什么 AI 不是「赢家通吃」市场?尽管 ChatGPT 用户数惊人,Sensor Tower 数据显示其「真实用户市场份额」(App+Web 合并去重)在 2026 年 3 月首次跌破 50%。原因有三:AI 使用是任务驱动而非社交网络驱动的,用户会根据不同任务切换工具;模型能力的差异化正在缩小;后发优势——Claude 在企业场景、DeepSeek 在长文本推理、Gemini 在多媒体处理上各有专长。Claude...

阿里 Qwen-Robot 三件套发布:中国具身智能的「会干」转折日
阿里 Qwen-Robot 三大模型拆解:从看懂到动手的逻辑6 月 16 日阿里巴巴发布的 Qwen-Robot 系列包含三个模型,分别解决具身智能的三个核心问题。操作模型 Qwen-RobotManip 采用 80 维统一动作表征,基于 38100 小时开源操作数据训练,实现跨硬件快速适配。移动模型 Qwen-RobotNav 引入任务自适应观察机制,在宇树科技 Go2 四足机器人上零样本部署(NVIDIA Jetson Thor,推理延迟 196ms),仅用单个低分辨率相机就可在陌生公寓中执行多房间任务。世界模型 Qwen-RobotWorld 基于物理规律认知,可预演动作轨迹并生成训练数据,跨操作、驾驶和导航场景预测符合物理规律的未来。6 月 16 日还有谁在具身智能赛道上出牌?同日,蚂蚁百灵发布 Ling & Ring 2.6 万亿参数三模型技术报告;理想汽车 Livis Day 定义具身智能汽车=电动车+职业司机+AI计算机+生活助手;法国 Genesis AI 发布非人形通用机器人 Eno(前 Google CEO...

OpenAI 投 1.5 亿美元建合作伙伴网络:从「卖 API」到「建渠道」,AI 的 Salesforce 时刻来了
OpenAI 宣布投资 1.5 亿美元建设合作伙伴网络,目标在 2026 年底前培训 30 万名认证顾问。

Fable 5 下架余波:白宫被指偏袒 OpenAI,印度借机掀起 AI 主权辩论
Fable 5 下架余波持续发酵:Gary Marcus 指控白宫偏袒 OpenAI 和亚马逊,印度科技领袖借机掀 AI 主权辩论。

Anthropic 秘密申请 IPO,9650 亿美元估值背后的 AI 资本豪赌
Anthropic 以 9650 亿美元估值秘密递交 IPO 申请,半年内收入暴增3倍至300亿美元以上。

Fable 5 上线不到一周被美国强制下架,AI 出口管制进入全新阶段
Anthropic 的 Fable 5 上线仅 4 天即被美国政府强制下架,AI 出口管制首次从卡硬件升级为卡模型本身。

ChatGPT 史上最大改版:从聊天机器人到「超级应用」,OpenAI 的终极赌注
据 Financial Times 6 月 7 日报道,OpenAI 正筹备 ChatGPT 自 2022 年上线以来最大改版,整合 Codex、图像生成与第三方应用,内部直言「Chat is dead」。背景是 9 月 IPO、估值 $852B。

一句「请帮我换邮箱」,Meta AI 客服交出了奥巴马白宫账号
攻击者用社交工程骗过 Meta AI 客服机器人,获取了奥巴马白宫、美国太空军高官、Sephora 等 Instagram 账号控制权。Meta 股价 6 月 5 日暴跌 5.51%。