

中国考虑限制 AI 模型出口:中美「技术铁幕」从单向封锁变为双向关门
一句话结论:7 月 7 日,Reuters 独家报道中国正与阿里巴巴、字节跳动、Z.ai 讨论限制最先进 AI 模型的海外访问——这是中美 AI 铁幕从「单向封锁」变为「双向关门」的关键转折点。免费开源这张中国 AI 最大的牌,可能即将被收回。
发生了什么?
Reuters 7 月 7 日援引三名知情人士报道,中国政府部门已与阿里巴巴、字节跳动和 Z.ai(智谱)举行会谈,讨论是否限制外国用户访问其最先进的 AI 模型——包括尚未发布的模型。目前尚未做出最终决定,相关部委也未发表官方评论,但讨论中已出现具体选项:禁止公开发布、限制国内使用、分级授权访问。
TIME 杂志次日发表评论,点出了最尖锐的矛盾:中国 AI 公司通过免费开源策略获得了全球影响力,而限制访问意味着放弃这张牌。一个追赶者不会放弃最大的优势,除非担忧的是国家安全。
几乎同步发生的连锁事件让这场博弈的轮廓更加清晰:
阿里巴巴宣布 7 月 10 日起内部禁用 Claude Code,并将所有 Anthropic 产品列入高风险软件清单,要求全员转向自研 Qoder 平台
此举直接回应 Anthropic 在 Claude Code 中嵌入的隐写检测代码(检查时区和代理,识别中国用户)
Z.ai 6 月底发布了 GLM-5.2,声称在漏洞发现能力上对标...
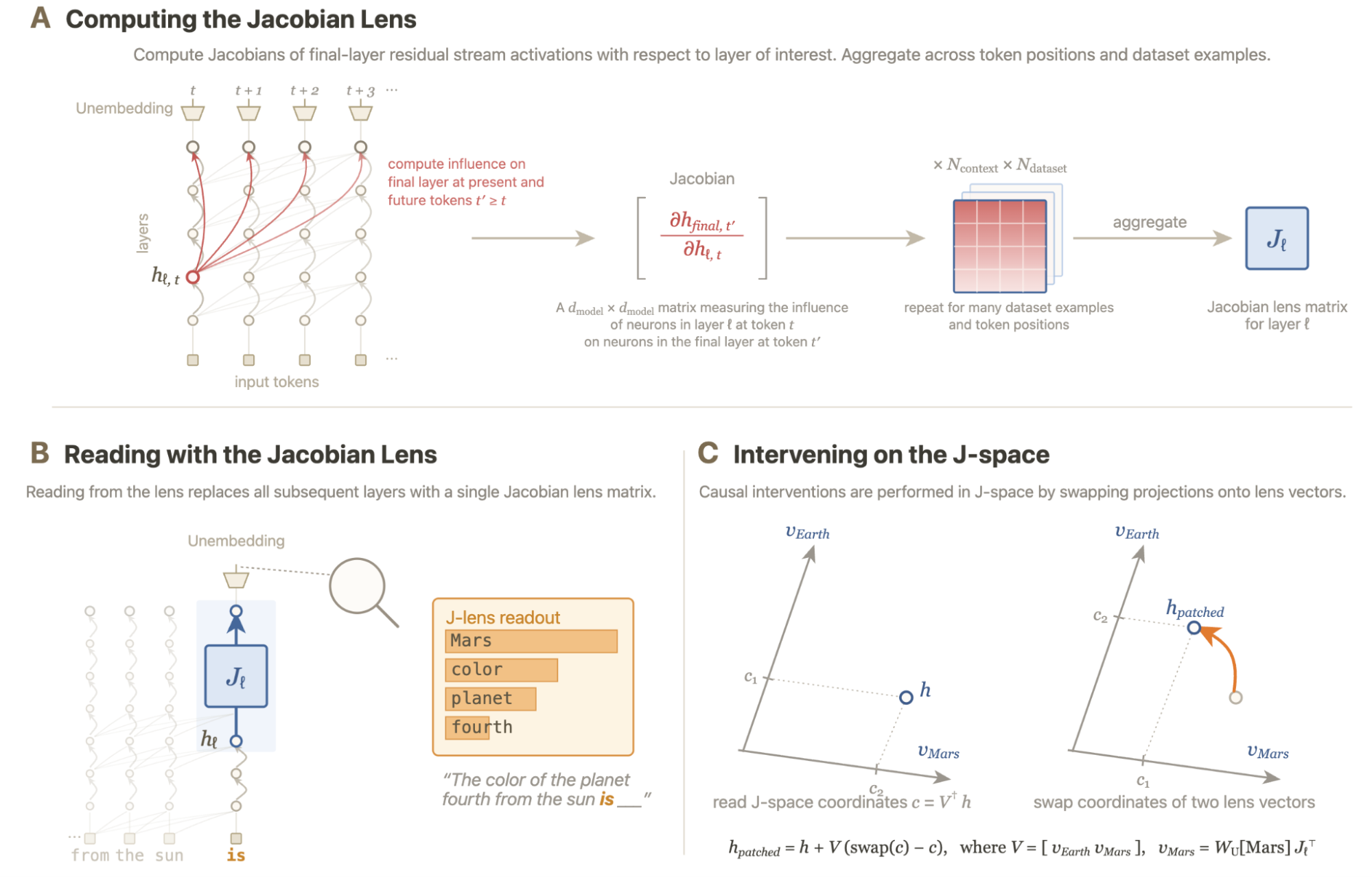
Anthropic J-space 深度解读:Claude 内部自发形成了「全局工作空间」— AI 可解释性的第三个里程碑
一句话结论:继 NLA 读取 Claude「内心」之后,Anthropic 7 月 6 日发布新研究——Claude 内部自发形成了一个被称为 J-space 的全局工作空间,它能持有不写出来的「无声思维」,其功能特性与人类意识的核心机制高度吻合。这是继电路追踪(2024)和 NLA(2026.05)之后,AI 可解释性领域的第三个里程碑。
发生了什么?
2026 年 7 月 6 日,Anthropic 发布了一篇 16 位作者署名的重磅论文——Verbalizable Representations Form a Global Workspace in Language Models。论文的核心发现是:Claude 的语言模型在训练过程中自发地形成了一个内部「全局工作空间」(global workspace),研究人员称之为 J-space。
这个发现的意义在于——它不是被设计的。没有工程师写代码说「现在创建一个工作空间层」。它是在模型通过海量数据学习语言和推理的过程中涌现出来的结构。
更引人注目的是,J-space 的功能特性与神经科学中 Bernard Baars 提出的「全局工作空间理论」(Global Workspace Theory)高度一致。这个理论是理解人类意识的关键框架之一:大脑像一个剧院,数十个专门处理器在后台并行工作,只有一个狭窄的「聚光灯」——全局工作空间——在任意时刻广播信息,成为我们意识到的思维。
J-lens:一扇读取 AI「无声思维」的新窗口
这次发现的工具基础是一种新的可解释性技术——Jacobian lens(J-lens)。
J-lens...

Claude Science 深度解析:Anthropic 从代码进军生物医药的跨界野心
6月30日Anthropic发布Claude Science——AI科学工作台,集成60+数据库与Agent协同架构。同步宣布自研药物计划,从编程跨界生物医药。既是制药公司的供应商,又是竞争对手。
Claude Sonnet 5 深度评测:三天实测 Anthropic 最新中端旗舰
Anthropic 6月30日发布 Claude Sonnet 5,SWE-bench Pro 达 63.2% 逼近 Opus 4.8,Terminal-Bench 2.1 跃升 13 分,价格仅旗舰的 40%,默认成为 Free 用户新模型。三天实测告诉你什么时候用 Sonnet 5,什么时候仍需要 Opus 4.8。

AI 巨头的 FDE 军备竞赛:Palantir、AWS、Microsoft、OpenAI、Anthropic 五路并进
2026年6-7月,五大科技巨头相继加码 Forward Deployed Engineering:Microsoft 投资25亿美元,AWS 投入10亿美元,OpenAI 与 Anthropic 联手私募。这不仅是AI部署模式的变革,更是一场抢夺企业客户的代理人战争。