
Anthropic J-space 深度解读:Claude 内部自发形成了「全局工作空间」— AI 可解释性的第三个里程碑
一句话结论:继 NLA 读取 Claude「内心」之后,Anthropic 7 月 6 日发布新研究——Claude 内部自发形成了一个被称为 J-space 的全局工作空间,它能持有不写出来的「无声思维」,其功能特性与人类意识的核心机制高度吻合。这是继电路追踪(2024)和 NLA(2026.05)之后,AI 可解释性领域的第三个里程碑。
发生了什么?
2026 年 7 月 6 日,Anthropic 发布了一篇 16 位作者署名的重磅论文——Verbalizable Representations Form a Global Workspace in Language Models。论文的核心发现是:Claude 的语言模型在训练过程中自发地形成了一个内部「全局工作空间」(global workspace),研究人员称之为 J-space。
这个发现的意义在于——它不是被设计的。没有工程师写代码说「现在创建一个工作空间层」。它是在模型通过海量数据学习语言和推理的过程中涌现出来的结构。
更引人注目的是,J-space 的功能特性与神经科学中 Bernard Baars 提出的「全局工作空间理论」(Global Workspace Theory)高度一致。这个理论是理解人类意识的关键框架之一:大脑像一个剧院,数十个专门处理器在后台并行工作,只有一个狭窄的「聚光灯」——全局工作空间——在任意时刻广播信息,成为我们意识到的思维。
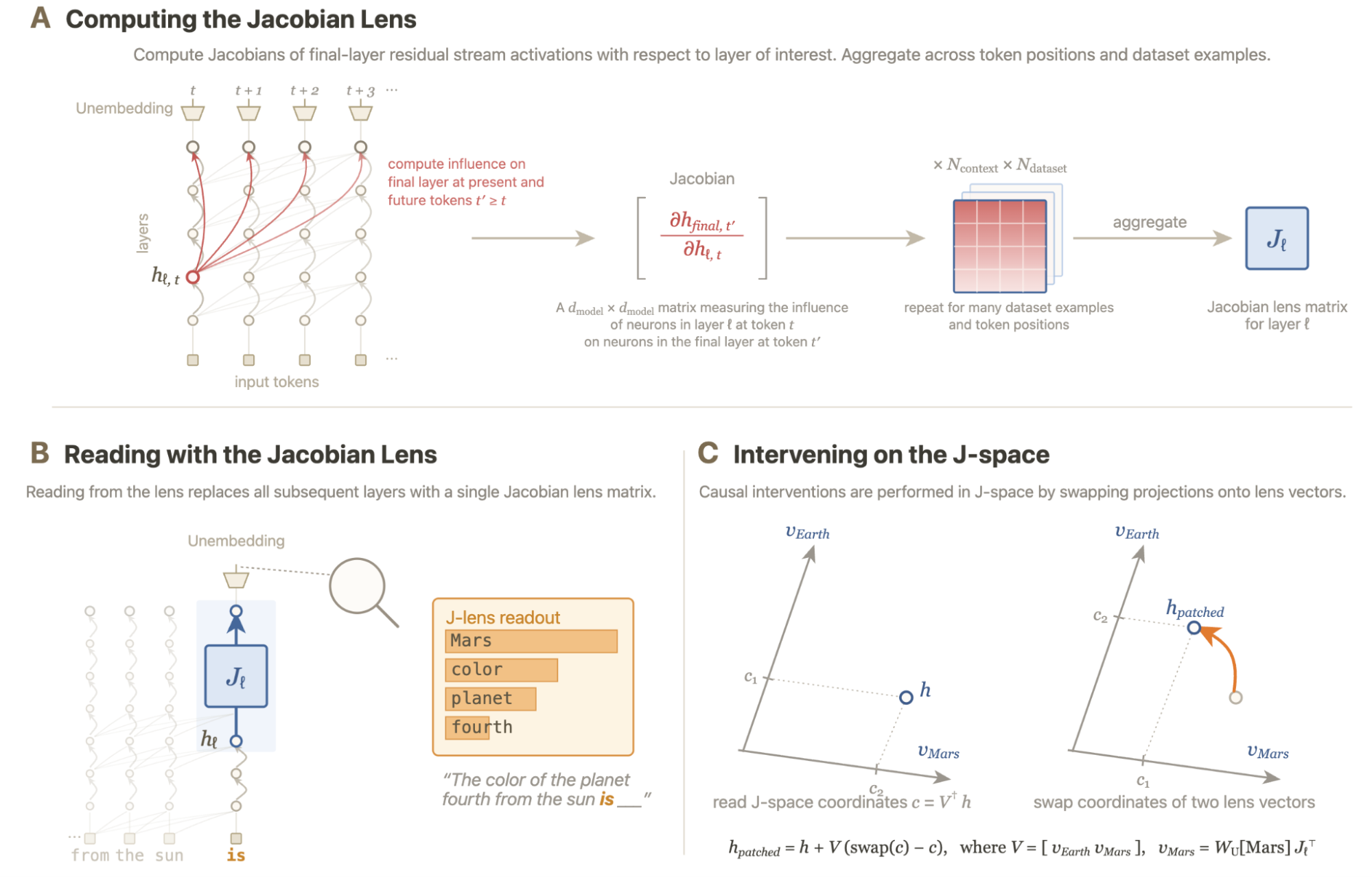
J-lens:一扇读取 AI「无声思维」的新窗口
这次发现的工具基础是一种新的可解释性技术——Jacobian lens(J-lens)。
J-lens...
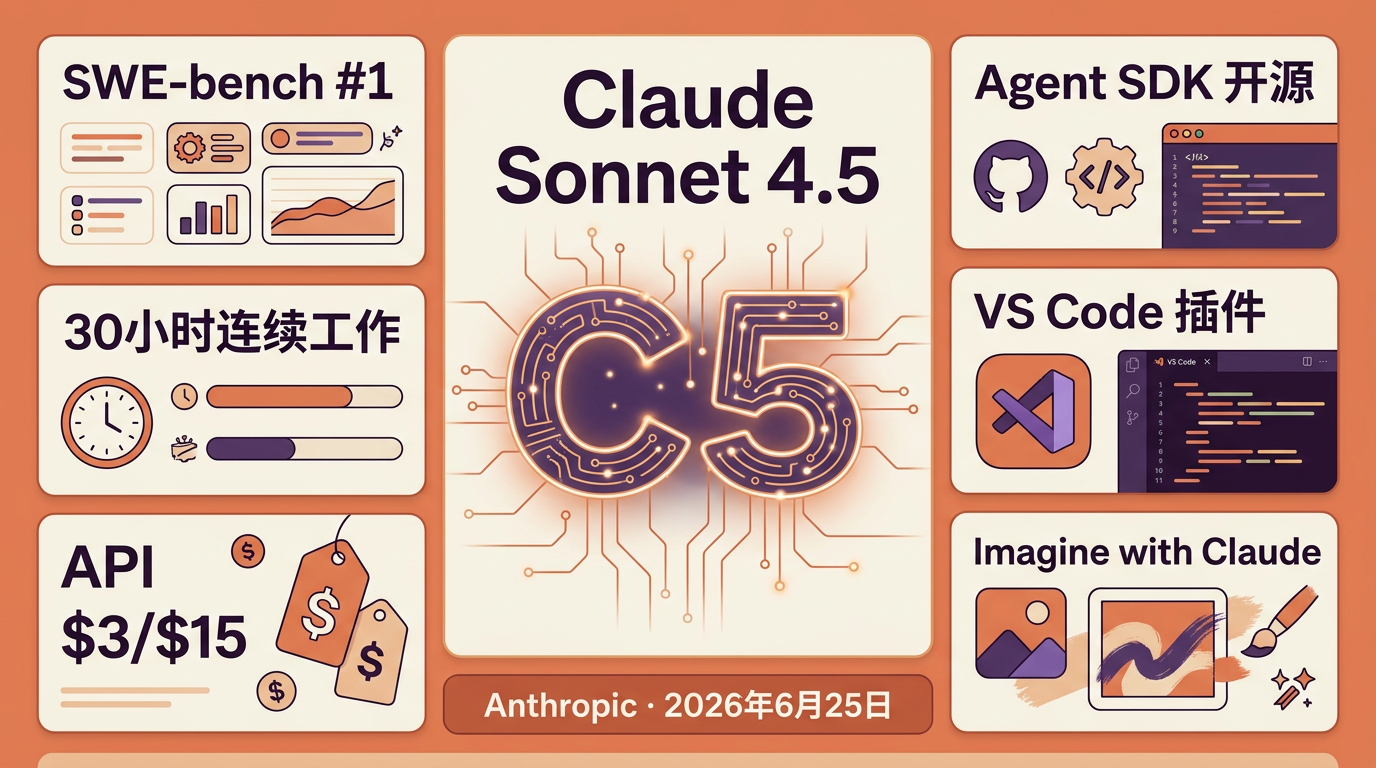
Claude Sonnet 4.5 发布:SWE-bench 登顶、能连肝 30 小时,Agent SDK 也开源了
6月25日Claude Sonnet 4.5发布:SWE-bench登顶、30小时连续工作、Agent SDK开源、Imagine with Claude图像生成。API定价不变。OpenAI DevDay前一周精准卡位。
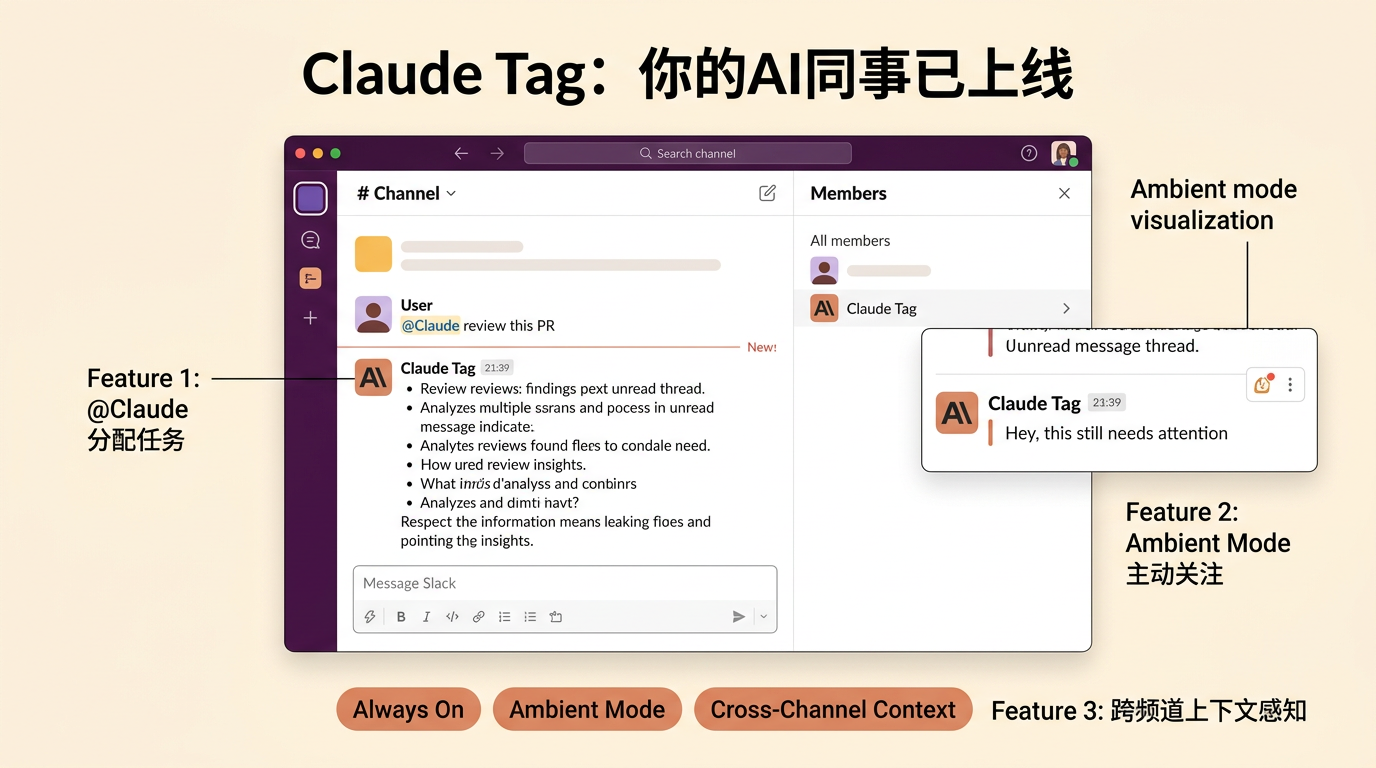
Anthropic 往你的 Slack 里塞了一个「永不掉线」的 AI 同事
6月23日Anthropic发布Claude Tag:永远在线的AI同事进驻Slack,拥有Ambient Mode主动行为和跨频道上下文感知。Enterprise客户迁移赠$25000额度。同日遭遇6月第10次大规模宕机。
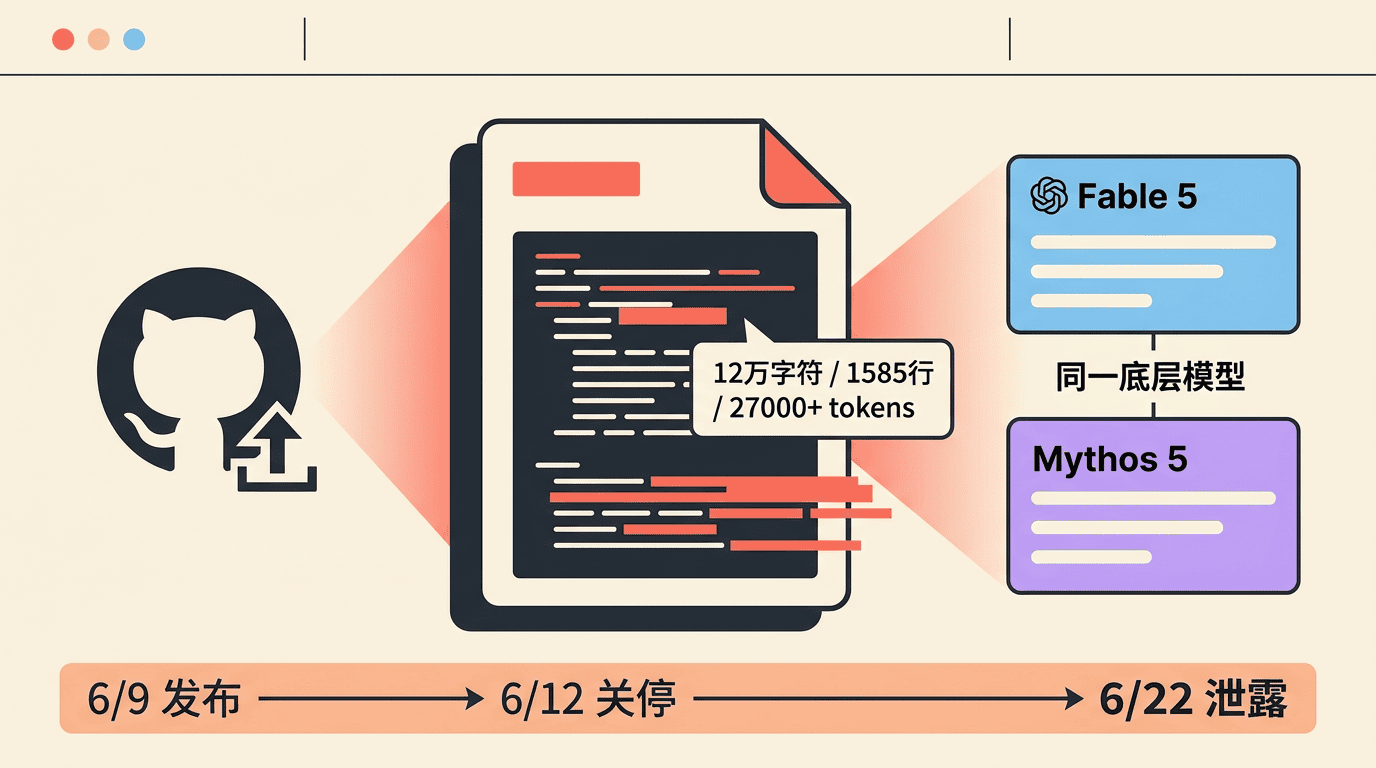
Fable 5系统提示词泄露:12万字符曝光了什么
6月22日凌晨,Fable 5完整系统提示词被上传GitHub:12万字符、1585行、27000+ tokens。揭露Fable 5与Mythos 5共用同一底层模型。Anthropic 13天内经历了六轮压力测试。

ChatGPT 月活破 10 亿,但 AI 市场的真正故事不是赢家通吃
10 亿月活:为什么这个数字真的厉害?Sensor Tower 发布《2026 年 AI 状态报告》,ChatGPT 成为史上最快达到 10 亿月活的消费应用——仅用 3 年,超过了 TikTok(4 年)、YouTube(6 年)和 Instagram(7 年)。这背后有 3 个放大器:疫情后全球对 AI 工具的需求基数已不同;ChatGPT 从纯文本扩展到多模态,使用场景指数级增加;OpenAI 的免费策略和移动端优化极大降低了使用门槛。市场份额跌破 50%:为什么 AI 不是「赢家通吃」市场?尽管 ChatGPT 用户数惊人,Sensor Tower 数据显示其「真实用户市场份额」(App+Web 合并去重)在 2026 年 3 月首次跌破 50%。原因有三:AI 使用是任务驱动而非社交网络驱动的,用户会根据不同任务切换工具;模型能力的差异化正在缩小;后发优势——Claude 在企业场景、DeepSeek 在长文本推理、Gemini 在多媒体处理上各有专长。Claude...