

5 月 6 日,Anthropic 在旧金山举办了第二届 Code with Claude 开发者大会。和去年发布新模型不同,今年他们没有发任何新模型——而是发了一套 Agent 基础设施。
Claude Code 的创作者 Boris Churnney 在台上说了一句话:”Anthropic 内部已经没有手写代码了。“与其说这是炫耀,不如说是一个信号:当一家 AI 公司自己的开发流程已经完全由 Agent 驱动,他们要解决的下一个问题就不是「模型够不够强」,而是「Agent 能不能稳定跑在生产环境里」。
这就是 Code with Claude 2026 的主题。Anthropic 为 Claude Managed Agents 发布了三个核心能力——Dreaming(跨会话记忆)、Outcomes(评分驱动的质量循环)、Multi-Agent Orchestration(多代理并行编排)——外加 Claude Finance 和 Add-ins 两个配套功能。这不是模型升级,是 Agent 运行时的基础设施升级。
Key Takeaways
– Dreaming 让 Agent 在会话之间自动提取跨会话模式并重组记忆,Harvey 测试中任务完成率提升约 6 倍
– Outcomes 用独立评分代理评估输出,任务成功率最多提升 10 个百分点——不需要换模型,只改了评估方式
– Multi-Agent Orchestration 支持 20 种子代理定义、25 并发线程,领导代理自动拆任务、分派、验证
– Anthropic 的战略信号很明确:Managed Agents 是平台,不是「模型 API + Agent 代码」
Dreaming 如何让 Agent 在「睡觉」时越变越聪明?
每个用过 Agent 的人都遇到过同一个问题:Agent 这次学会了,下次从头再来。
标准 Agent 记忆只在单次会话内有效。你告诉它「这个文件的 JSON 格式不对,要用 YAML」,它这次记住了;但下次开新会话,同样的错误还会出现。Dreaming 就是解决这个问题的。
Dreaming 是一个在会话之间运行的后台定时进程。它审查 Agent 的历史会话和记忆存储,提取跨会话的模式——比如重复出现的错误、多个 Agent 独立收敛到的相同工作流、团队层面的偏好设置——然后把这些模式写成结构化的记忆,供下一次会话预加载。用 Anthropic 的话说,它能看到「单个 Agent 自己看不到的模式」。
它和标准 Agent 记忆的关系是这样的:标准记忆捕捉的是「这个 Agent 在这次任务中学到了什么」,Dreaming 提炼的是「所有 Agent 在所有会话中反复验证过的规律」。

引用胶囊:「Dreaming 是一个在 Agent 会话之间运行的后台进程,它从历史会话中提取模式并生成策划记忆,让 Agent 随着使用变得越来越聪明。」——Anthropic 官方博客,2026 年 5 月
Harvey 的测试数据最直观:使用 Dreaming 后,任务完成率提升了约 6 倍。关键细节是——模型没换,只是记忆系统变了。之前每个会话都在重新学习文件类型的处理变通方案和特定工具的调用模式,现在这些知识以「机构记忆」的形式沉淀下来了,不需要每次都从头学。据 NerdLevelTech 报道,Harvey 的改善纯粹来自累积的机构知识(文件类型变通方案、工具特定模式),而非模型升级。
不过需要指出,跨会话记忆本身不是新技术。开源 Hermes Agent 框架提供跨会话记忆已经快一年了。Anthropic 的贡献是把这件事做成了托管默认值——团队不需要自己搭建记忆基础设施,开个开关就行。对于没有工程资源自建记忆层的团队来说,这省掉的是一整块基础设施的工作量。
Dreaming 提供两种控制级别:
1. 自动更新:Dreaming 直接写入记忆,不需要人工审核
2. 审核闸门:所有建议的变更必须经过人工审批才能持久化——适合受监管环境
目前 Dreaming 是研究预览版,需要填申请表才能开通,不是默认开启。访问门槛说明 Anthropic 还在验证这项能力的边界——毕竟让 Agent 自动修改自己的记忆,对生产系统来说是有风险的。
Outcomes 为什么能用一个独立 Agent 给另一个 Agent 打分?
如果说 Dreaming 解决的是「Agent 记不住」,Outcomes 解决的是「Agent 写完了但质量不行」。
Outcomes 的机制很简洁:你写一个评分标准(rubric),定义「成功是什么样子」。任务 Agent 完成输出后,另一个独立的 Claude 实例(评分 Agent)用你的评分标准评估这份输出。关键是评分 Agent 看不到任务 Agent 的推理链——它只看最终输出。
为什么这个设计很重要?因为大语言模型给自己打分时,存在严重的自我确认偏差——它倾向于认同自己刚才的推理。Anthropic 用独立的上下文窗口运行评分 Agent,就是在重建「一个没参加过你会议的评审人」的视角。
如果评分不通过,评分 Agent 会明确指出哪里需要改,任务 Agent 重新执行。这个循环持续到评分达标为止。
引用胶囊:「Outcomes 是一个由评分标准驱动的评估循环,用独立的评分代理评估输出。内部测试显示任务成功率提升最多 10 个百分点,最大收益出现在最难的问题上。」——Anthropic 官方博客,2026 年 5 月

内部基准测试数据:
| 指标 | 提升幅度 |
|---|---|
| 整体任务成功率 vs 标准提示循环 | 最多 +10 个百分点 |
| .docx 文件生成质量 | +8.4% |
| .pptx 文件生成质量 | +10.1% |
这个数据背后有一个值得注意的结论:文档生成质量提升 10%,不是靠换模型,而是靠改评估方式。这意味着很多 Agent 输出质量问题的瓶颈不在模型能力,而在于缺乏有效的质量反馈机制。一个结构化的评分标准 + 独立评估,比换更强的模型更划算。
Wisedocs 的案例可以作为参考:据 MindStudio 报道,他们用 Outcomes 建了一个文档质量检查 Agent,每次审查按内部指南自动打分。结果是审查速度提升 50%,同时保持与团队标准对齐。
Outcomes 还配套了 Webhook 通知——你定义好评分标准、启动 Agent,完成后通过 HTTP 回调通知你,不需要轮询或保持长连接。对长时间运行的 Agent 任务来说,这是从「等它跑完」到「跑完了叫我」的体验升级。
Outcomes 目前是公开测试版,通过 managed-agents-2026-04-01 beta header 即可使用。
Multi-Agent Orchestration 如何让一群 Agent 并行协作?
单独一个 Agent 处理复杂任务,就像让一个人同时查日志、看部署历史、分析指标、翻工单——能做,但慢,而且容易漏。
Multi-Agent Orchestration 的架构很简单:一个领导 Agent + 多个专家子 Agent,共享文件系统,并行执行。
流程是这样的:领导 Agent(coordinator)接收任务后,把它拆成子任务,然后分派给不同的专家子 Agent。每个子 Agent 有自己的模型、提示词和工具集——可以是一种子 Agent 的多份副本,也可以是不同类型的子 Agent。子 Agent 在共享文件系统上并行跑,完成后把结果交回给领导 Agent 上下文中。领导 Agent 可以在中途检查进度,因为「事件是持久化的,每个 Agent 都记得自己做了什么」。
当前 Beta 版的规模上限:
– 每个编排配置最多 20 种子 Agent 定义
– 最多 25 个并发线程
– 编排器可以启动同一种子 Agent 的多个副本

引用胶囊:「Multi-Agent Orchestration 让一个领导 Agent 把工作拆成片段,分派给有各自模型、提示词和工具的专业子 Agent,在共享文件系统上并行执行。每一步都可以在 Claude Console 中追溯。」——Anthropic 官方博客,2026 年 5 月
Netflix 的应用场景很有代表性:据 InfoQ 报道,他们用 Multi-Agent 分析来自多个来源、数百个构建的日志,找出重复出现的问题。过去这种分析需要工程师手动跨系统查找,现在一个领导 Agent 启动后,子 Agent 并行扫部署历史、错误日志、性能指标和支持工单,然后把发现汇总回来。
可追溯性是一个容易被忽视但至关重要的设计。Claude Console 记录每一步——哪个 Agent 做了什么、按什么顺序、为什么这样做。并行多 Agent 跑起来之后,如果某个子 Agent 卡住了,没有时间线级别的追踪,调试基本是大海捞针。
Multi-Agent 也是公开测试版,和 Outcomes 一样通过 beta header 使用。
定价没变,但供应商锁定问题值得担心吗?
这三个新能力的定价和 2026 年 4 月 Managed Agents 刚发布时一样:标准 Claude API token 费率 + $0.08/活跃会话小时(空闲会话不收费)。
但也出现了一个值得关注的批评声音:供应商锁定。Anthropic 现在拥有了你的 Agent 记忆、评估标准和编排逻辑——这些都在他们控制的基础设施上运行。Webhook 层进一步扩展到了事件处理。如果你的团队需要把记忆和编排放在自己的基础设施上,或者未来可能换模型,像 LangGraph 或 CrewAI 这样的开放框架仍然更灵活——代价是「更多的基础设施要自己搭」。
附赠:Claude Finance 和 Add-ins
除了三大核心能力,Code with Claude 2026 还发布了两个值得注意的功能:
Claude Finance 是一套面向金融服务业的 10 个预构建 Agent:包括 Pitch 构建器、会议准备工作、市场研究员、评估审核员、月末结算员等。每个 Agent 可以作为协作插件、Claude Code 组件或 Managed Agent 部署。Anthropic 还发布了一份完整的 Cookbook,方便团队理解和修改每个 Agent。同步上线了三个行业连接器:Dun & Bradstreet(企业身份)、Fiscal AI(市场分析)和 Verisk(保险核保)。
Add-ins 是一个设计理念上的转变:Claude 不再通过 MCP 或连接器「读取」软件文件,而是直接嵌入软件内部工作——获得「软件原生上下文」,如文档模板、链接的电子表格、已有的格式约定。从「Claude 能读你的 Word 文件」到「Claude 在 Word 里像一个人类那样工作」,这个方向值得关注,但实际效果还需要验证。
Anthropic 的平台战略:Agent 的基础设施层
回到 Boris 那句话——「Anthropic 内部已经没有手写代码了」——放在整个大会的语境里看,它的意思不是「大家都用 Claude Code 写代码了」,而是「代码的生产方式被 Agent 接管了,现在的核心问题不是代码怎么写,而是 Agent 怎么管」。
Code with Claude 2026 的五个发布——Dreaming、Outcomes、Multi-Agent、Claude Finance、Add-ins——分别对应 Agent 生产化的五个瓶颈:记忆退化、质量不可控、单 Agent 复杂度上限、行业特定工作流、软件原生上下文。
这不是模型能力的竞争,是 Agent 基础设施的竞争。Anthropic 在告诉市场:我们不卖 API,我们卖的是跑 Agent 的平台。记忆、评估、编排这些过去需要开发者自己搭的东西,现在成了平台的默认能力。
对于 AI 开发者和技术决策者来说,这意味着一个评估框架的切换:选 Agent 方案时,不再只比较模型跑分,还要比较记忆系统的成熟度、质量评估机制的可靠性、编排架构的生产就绪程度。模型强只是入场券,基础设施才是护城河。
常见问题
Dreaming 和普通 Agent 记忆有什么区别?
普通 Agent 记忆是单次会话内的临时记忆。Dreaming 是在会话之间运行的定时进程,它审查所有历史会话和记忆,提取跨会话的重复模式(如常见错误、工作流趋同),将这些提炼后的「机构知识」写回记忆供下次使用。Harvey 在启用 Dreaming 后任务完成率提升了约 6 倍,而模型本身没有更换。
Outcomes 的评分循环会不会增加延迟?
会。因为输出需要被独立评分 Agent 评估,不通过还会重新生成,总体耗时比单次生成长。但 Wisedocs 的实际案例显示,虽然每次审查多了评分步骤,整体审查速度反而快了 50%——因为减少了人工复查和返工的时间。对于质量敏感的场景(文档生成、报告撰写),这个延迟换来的质量提升是值得的。
Multi-Agent 编排和直接并发调用 API 有什么区别?
直接并发调用 API 需要你自己管理任务分配、上下文聚合、错误处理和并行协调。Multi-Agent Orchestration 提供了声明式配置(定义子 Agent、模型、工具),领导 Agent 在运行时自动决策如何拆分和分派任务,并提供 Claude Console 中的完整时间线追踪。对于需要多种工具、多个信息源的复杂分析任务,这层编排抽象省掉的是大量胶水代码。
这些功能会锁定在 Anthropic 平台上吗?
目前是的。Dreaming 的记忆存储、Outcomes 的评分标准、Multi-Agent 的编排逻辑都运行在 Anthropic 管理的基础设施上。如果你的团队需要完全控制这些组件,或可能未来切换模型供应商,开源框架如 LangGraph、CrewAI 或 Hermes 提供了更大的灵活性,但代价是需要自行搭建和运维更多基础设施。
这三个功能什么时候能正式上线?
Dreaming 是研究预览版,需要申请才能开通,正式上线时间未公布。Outcomes 和 Multi-Agent Orchestration 已经是公开测试版,可通过 API beta header 使用。Anthropic 通常的 beta 到 GA 周期在 1-3 个月左右。
结语
Code with Claude 2026 最值得记住的不是某个具体功能,而是一个命题:Agent 生产化的瓶颈不是模型能力,而是模型周围的基础设施。
Dreaming 解决记忆退化,Outcomes 解决质量不可控,Multi-Agent 解决单 Agent 能力上限。这三件事加起来,是在把 Agent 从「能跑通 Demo」推进到「能稳定跑生产」。对于一个正在决定 Agent 方案的技术团队来说,这个推进方向——而不是某个模型的跑分——才是真正值得关注的信号。
参考来源
– Anthropic, “New in Claude Managed Agents: dreaming, outcomes, and multiagent orchestration”,检索于 2026-05-25
– ZDNET, “Your Claude agents can ‘dream’ now”,检索于 2026-05-25
– InfoQ, “Anthropic’s Code with Claude Announces Managed Agents”,检索于 2026-05-25
– MindStudio, “Code with Claude 2026: 5 New Agent Features Anthropic Just Shipped”,检索于 2026-05-25
– NerdLevelTech, “Claude Managed Agents: Dreaming, Outcomes, Multiagent Orchestration”,检索于 2026-05-25
– BitsMinds, “Code with Claude 2026: Anthropic Reveals Dreaming Agents, Routines”,检索于 2026-05-25
Marketing Skills — 37K 星 AI Agent 营销技能库:CRO、SEO、文案、增长工程一站式 Agent 工具包
一句话结论:Marketing Skills 是 Corey Haines 构建的一个开源 AI Agent 营销技能库,已在 GitHub 获得 37,000+ Stars。它包含 36 个结构化营销技能,覆盖转化率优化(CRO)、文案写作、SEO 审计、数据分析、增长工程等领域,让 AI 编码 Agent 变身专业营销顾问。
项目介绍
Marketing Skills 是一个遵循 Agent Skills 规范 的技能集合。每个技能是一个 Markdown 文件,给 AI Agent 注入特定营销任务的专业知识和结构化工作流。当你在项目中添加这些技能后,Agent 能识别你正在做营销任务,自动应用正确的框架和最佳实践。
作者 Corey Haines 是 Conversion Factory 和...
AI Job Search — 7K 星 Claude Code 求职框架:让 AI Agent 帮你投简历、写求职信、模拟面试
一句话结论:AI Job Search 是一个基于 Claude Code 的 AI 求职框架,在 GitHub 上已获得 7,000+ Stars。它把 Claude Code 变成一个全能求职助手:自动评估岗位匹配度、定制简历、写 Cover Letter、准备面试。TypeScript 开发,MIT 开源。
项目介绍
AI Job Search 由丹麦开发者 Mads Lorentzen 创建,核心思路是:把求职变成一个结构化的、AI 可执行的流水线。你只需填写个人资料(CV、技能、经历),Claude Code 会自动完成后续所有步骤。
核心工作流(自我画像→岗位匹配评估→起草-审查申请流水线)是语言和国家无关的。内置的丹麦求职门户技能(Jobindex、Jobnet 等)可以替换为你当地的求职网站。项目还提供了 /add-portal 命令自动生成新求职门户的搜索技能。
核心功能
自我画像:填写 CV、技能、工作偏好后,Agent 自动建立你的职业画像
岗位匹配评估:Agent 分析岗位描述,评估匹配度,给出申请建议
简历定制:根据目标岗位自动调整简历重点和关键词
Cover Letter 生成:起草-审查双 Agent 流水线,确保质量
面试准备:基于岗位描述生成常见问题和回答建议
LinkedIn 全球搜索:通过公开...
Agent Skills — Addy Osmani 开源的 AI 编码 Agent 24 技能包:从 Spec 到 Ship 全生命周期工程规范
一句话结论:Agent Skills 是 Google Chrome 工程总监 Addy Osmani 开源的生产级 AI 编码 Agent 技能包,24 个技能覆盖 Define→Plan→Build→Verify→Review→Ship 完整开发周期。支持 Claude Code、Cursor、Codex、Copilot 等 70+ 工具。将 Google 工程文化的最佳实践编码为 Agent 可执行的结构化工作流。
项目介绍
AI 编码 Agent 默认走最短路径——跳过 Spec、跳过测试、跳过安全审查。Agent Skills 给 Agent 注入了资深工程师的工程纪律:什么时候写 Spec、测试什么、怎么审查、什么时候上线。这不是通用 Prompt,而是经过 Google 工程文化验证的、结构化的、有明确验证标准的工程工作流。
每个技能包含:流程步骤、验证检查点、反借口表(阻止 Agent 跳过步骤)、红线标记。设计理念来自
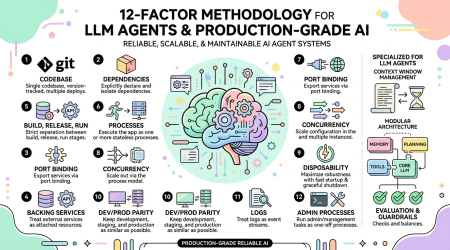
12-Factor Agents — 构建生产级 LLM 应用的 12 条原则:从原型到可靠产品的工程方法论
一句话结论:12-Factor Agents 是 HumanLayer 提出的构建生产级 LLM 应用的 12 条工程原则,受 12-Factor App 方法论启发。它回答了一个核心问题:什么原则能让我们构建的 LLM 应用真正达到可以交付给生产客户的质量标准?
项目介绍
作者 Dexter 在构建 AI Agent 产品时发现一个普遍问题:大多数 Agent 项目能达到 70-80% 的质量,但突破 80% 进入生产级别需要深入了解框架内部。他提炼了 12 条原则,帮助开发者从一开始就用正确的方式构建可靠的 LLM 应用。
核心洞察:即使 LLM 持续指数级增长,依然存在核心工程技巧让 LLM 应用更可靠、更可扩展、更易维护。最关键的是——你不需要全盘重写来采用 Agent 架构,可以逐步将 Agent 的模块化概念融入现有产品。
12 条原则
自然语言优先 — 用自然语言定义...
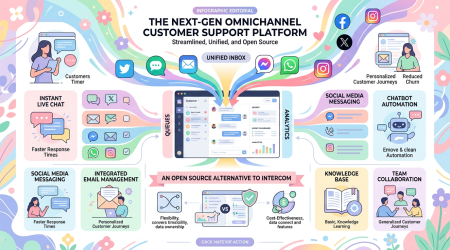
Chatwoot — 30K 星开源客服平台:自托管替代 Intercom/Zendesk,支持全渠道 + AI Agent
一句话结论:Chatwoot 是 GitHub 上 30,000+ Stars 的开源客服平台,自托管替代 Intercom 和 Zendesk。支持网站实时聊天、邮件、WhatsApp、Facebook 等全渠道收件箱,内置 AI 助手和知识库。Ruby on Rails 开发,数据完全私有。
项目介绍
Chatwoot 是现代开源客服支持平台,为需要完全控制客户数据的企业设计。它将所有客户对话集中到一个强大的收件箱,无论客户从哪里联系你。支持 网站实时聊天、邮件、Facebook、Instagram、Twitter、WhatsApp、Telegram、Line、SMS 等渠道。
核心优势:完全自托管,数据归你所有。适合有合规要求(GDPR、HIPAA)或不想把客户数据交给第三方 SaaS 的企业。
核心功能
全渠道收件箱:网站、邮件、社交、即时通讯,一个界面管理所有对话
AI 助手:自动回复、意图识别、情感分析、对话摘要
知识库:内置帮助中心,支持多语言
联系人管理:客户画像、交互历史、自定义字段
团队协作:对话分配、内部备注、预设回复(Canned Responses)
自动化:基于规则的自动分配、标签、触发器
API 和 Webhook:完整 REST API,支持自定义集成
移动端:React Native 构建的 iOS/Android App
安装方式
# Docker 一键部署(推荐)
docker run -p 3000:3000 chatwoot/chatwoot
# 手动安装(Ubuntu)
git clone https://github.com/chatwoot/chatwoot.git
cd...
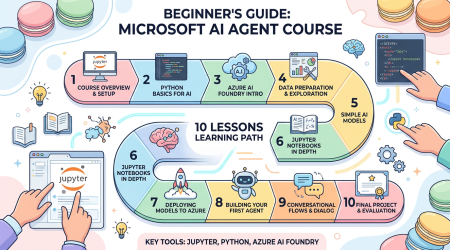
AI Agents for Beginners — 微软官方 AI Agent 入门课程:10 节课从概念到代码
一句话结论:AI Agents for Beginners 是微软官方的 10 节 AI Agent 入门课程,使用 Microsoft Agent Framework (MAF) 和 Azure AI Foundry,从概念到代码带你构建第一个 AI Agent。支持中文等多语言,免费开源。
项目介绍
这是微软官方出品的 AI Agent 入门课程,在 GitHub 上开源。每节课包含 视频讲解 + 文字教程 + Python 代码示例 (Jupyter Notebook),使用 Microsoft Agent Framework 和 Azure AI Foundry...
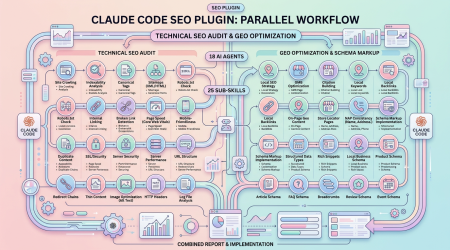
Claude SEO — 11K 星 Claude Code SEO 插件:25 子技能 + 18 专业 Agent 并行审计
一句话结论:Claude SEO 是一个开源的 Claude Code SEO 分析插件,已在 GitHub 获得 11,000+ Stars。它拥有 25 个子技能和 18 个专业 Agent,可并行执行技术 SEO、E-E-A-T 评分、Schema.org 标记、GEO/AEO(AI 搜索优化)、本地 SEO、电商 SEO、国际 SEO 等全方位审计。MIT 开源,完全离线可用。
项目介绍
Claude SEO 由 Daniel Agrici 开发,是目前功能最全面的开源 SEO 分析工具。它遵循 Google 官方 AI 优化指南 和 2025 年...
Pixelle-Video — 开源 AI 全自动短视频引擎:输入主题,3 分钟出视频
一句话结论:Pixelle-Video 是一个开源的 AI 全自动短视频生成引擎,输入一个主题即可自动完成脚本撰写、AI 配图、语音合成、背景音乐和一键合成视频。支持多种 AI 模型和 TTS 方案,完全免费方案仅需本地 Ollama + ComfyUI。中文友好。
项目介绍
Pixelle-Video 由 ATH-MaaS 团队开发,是一个"输入主题,3 分钟出视频"的全自动 AI 短视频引擎。不需要视频编辑经验,不需要复杂配置。基于 ComfyUI 架构,支持预设工作流和自定义能力扩展。
核心功能
全自动生成:输入主题 → 自动出完整视频
AI 智能文案:基于主题自动生成解说词
AI 配图/视频:每句解说词配精美 AI 插图
AI 语音合成:支持 Edge-TTS、Index-TTS 等主流方案
背景音乐:自动添加 BGM 增强氛围
多种视觉风格:多个模板打造独特视频风格
灵活尺寸:支持竖屏、横屏等多种视频尺寸
多 AI 模型:GPT、千问、DeepSeek、Ollama 等
成本方案
方案配置成本完全免费Ollama (本地) + 本地 ComfyUI$0推荐方案千问 LLM +...
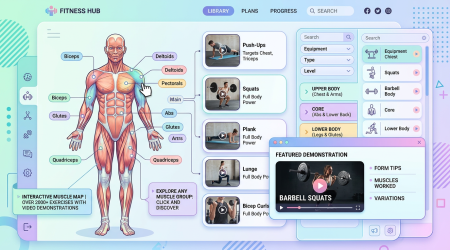
MuscleWiki — 2000+ 动作交互式健身库:点击肌肉,秒查训练动作
一句话结论:MuscleWiki 是一个免费的交互式健身动作库,收录 2,000+ 个动作和 7,500+ 个视频演示。通过交互式肌肉地图,点击任意肌肉即可看到针对训练动作。提供免费 API,适合健身 App 开发者集成。
项目介绍
MuscleWiki 以独特的交互式肌肉地图为核心体验。人体模型上标注了 45 个肌肉群,点击任意肌肉即可显示该部位的针对性训练动作,每个动作都配有视频演示和分步文字说明。是目前互联网上最直观的健身动作查询工具。
核心功能
交互式肌肉地图:45 个肌肉群可视化标注,点击即查
2,000+ 动作库:覆盖全身所有肌群
7,500+ 视频演示:专业动作教学视频
分步文字指南:每个动作的详细执行说明
免费 API:供开发者集成到健身 App 中
移动端适配:响应式设计,手机浏览器完美体验
API 使用
# 获取所有动作
curl https://api.musclewiki.com/v1/exercises
# 按肌肉群筛选
curl https://api.musclewiki.com/v1/exercises?muscle=biceps
# 完整 API 文档见
# https://api.musclewiki.com/documentation
适用场景
健身 App:嵌入动作教学视频和文字指南
个人训练:查询不熟悉的动作正确做法
教练教学:快速展示动作给学生看
内容创作:健身文章和视频的参考资料
FAQ
MuscleWiki 免费吗?
网站完全免费。API 有免费层,适合个人项目和中小型应用。商业大规模使用需查看 API 定价。
和 YouTube 健身视频有什么区别?
MuscleWiki 的独特优势是按肌肉定位。你不知道动作名字,但你">>知道想练哪个部位——点击肌肉就能找到所有针对该部位的动作。
相关链接
MuscleWiki 官网
MuscleWiki API
Exercises...
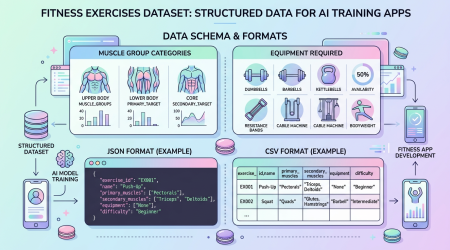
Exercises Dataset — 433 个健身动作开源数据集:为你的健身 App 和 AI 模型提供结构化数据
Exercises Dataset 提供 433 个健身动作的结构化数据,并整合 MuscleWiki 动作演示与 DAREBEE 免费训练计划,适合健身 App、AI 模型和个人训练参考。
评论 (2)
[…] Build 2026 全复盘:自研 MAI 模型登场 · Claude Managed Agents 三大新能力详解 · 硅谷的 AI […]
[…] Claude Managed Agents 三大新能力详解:Dreaming、Outcomes 和多代理编排,Agent […]
评论被关闭。