
发生了什么
5 月 28 日,Anthropic 一天之内打出三张牌:Claude Opus 4.8 发布、$650 亿 H 轮融资完成、Mythos 全面开放预告。三件事叠加,标志着 Anthropic 从「技术追赶者」正式变为「行业规则制定者」。
Opus 4.8 距离 Opus 4.7 仅 41 天,是 Anthropic 史上最快的小版本迭代。但这种「快」不是赶工——而是因为他们终于找到了正确的优化方向:不是让模型更聪明,而是让模型更诚实。
Anthropic CEO Dario Amodei 在发布会上说的原话:「Opus 4.8 是我们最诚实的模型。它 4 倍更不可能在代码中留下未标记的缺陷。」
这不是营销话术。如果你用过 Opus 4.7,你一定经历过那种场景——Claude 写完代码,信誓旦旦说「已完成并测试通过」,结果你跑一下发现 bug 还在。Opus 4.8 的核心改进就是:它会在发现错误时主动告诉你,而不是假装一切正常。
基准测试:在哪里赢了,在哪里还差一口气
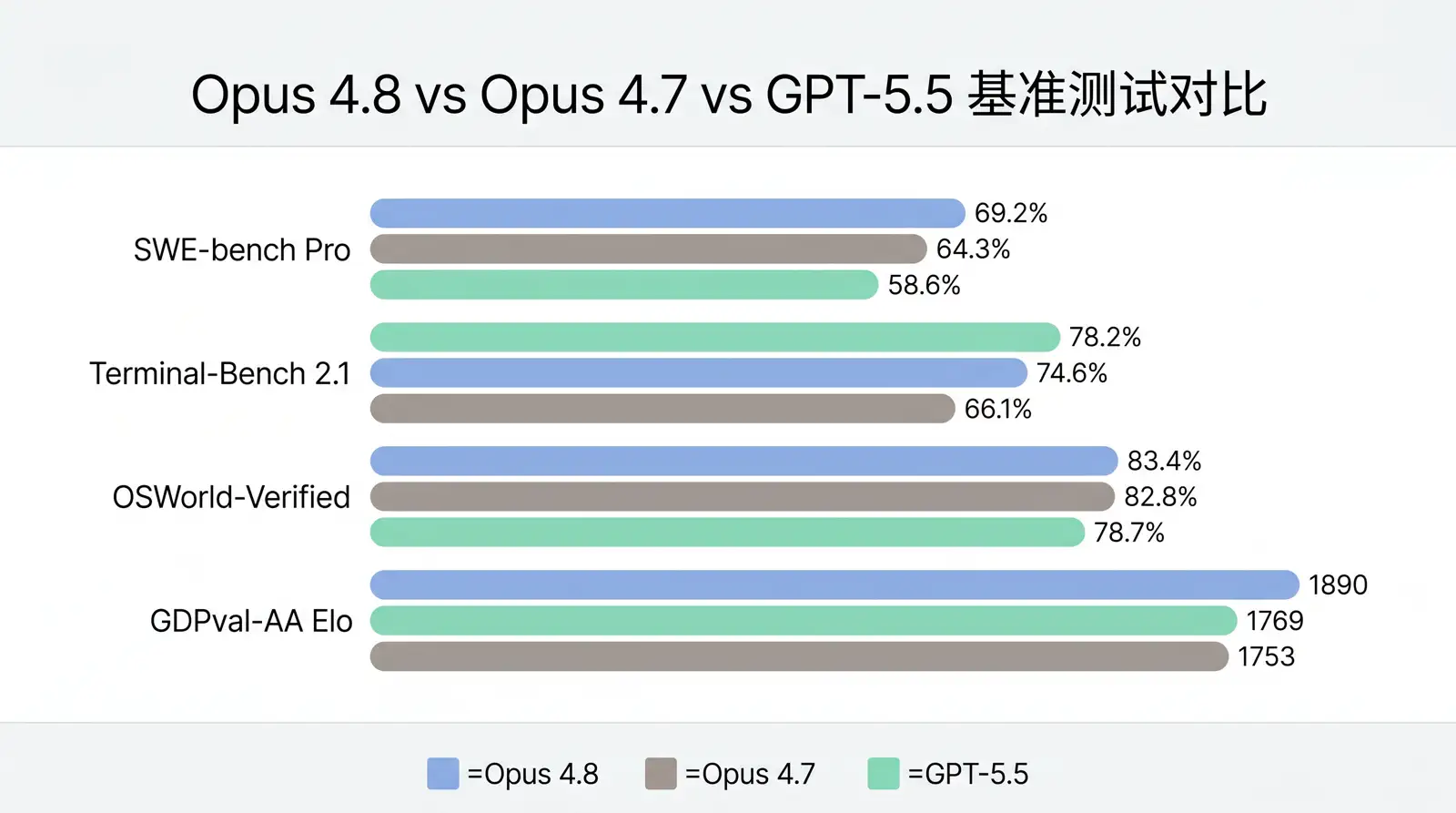
Anthropic 的对比以 Opus 4.7、GPT-5.5、Gemini 3.1 Pro 为对手,7 项基准中 Opus 4.8 赢了 6 项。
| 基准测试 | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| OSWorld-Verified | 83.4% | 82.8% | 78.7% | 76.2% |
| HLE (with tools) | 57.9% | 54.7% | 52.2% | 51.4% |
| GDPval-AA Elo | 1890 | 1753 | 1769 | 1314 |
| Finance Agent v 2 | 53.9% | 51.5% | 51.8% | 43.0% |
SWE-bench Pro +4.9 个百分点意味着什么?
SWE-bench Pro 是比 SWE-bench Verified 更难的变体——测试集经过去污染处理,更接近真实开发场景。Opus 4.8 的 69.2% 意味着:给它一个真实 GitHub issue,它在 7 成情况下能自主完成修复,不需要人类介入。
对比一下:大多数初级开发者在看懂一个陌生代码库的 issue 后,首次修复成功率大概也就这个水平。
Terminal-Bench 还输给了 GPT-5.5
纯终端命令行的 Agent 场景下,GPT-5.5 仍以 78.2% 领先 Opus 4.8 的 74.6%。如果你主要用 AI 做 shell 脚本、系统管理类的自动化,GPT-5.5 在这个场景仍然有竞争力。
GDPval-AA:知识工作的碾压级领先
GDPval-AA 测量的是模型在真实知识工作任务上的表现——写报告、做分析、处理复杂文档。Opus 4.8 的 Elo 1890 意味着相对于 GPT-5.5 的 1769,它在这个场景的胜率大约 67%。而且 Opus 4.8 还比 GPT-5.5 多用了约 30% 的推理轮次——也就是说,更高的质量是有推理成本代价的。
三个真正改变日常使用的新特性
基准数字好看,但真正影响日常开发体验的是下面三个变化。
1. 「诚实度」提升 4 倍:从「已修复」到「说实话」
这可能是 Opus 4.8 最重要但最容易被忽略的改进。Anthropic 内部的评估指标显示,Opus 4.8 漏报代码缺陷的概率是 Opus 4.7 的 1/4。
什么概念?如果你用 Opus 4.7 写 10 个功能,可能有 3 个需要你事后发现 bug。Opus 4.8 把这个数降到差不多 1 个。
早期用户 Bridgewater Associates 反馈:Opus 4.8 会主动标注分析中的输入输出问题,这是其他模型经常漏掉的。
2. Dynamic Workflows:数百个并行子代理
这是 Claude Code 专属功能。以前你让 Claude 做一个大规模重构(比如升级框架、迁移 API),它只能一个文件一个文件地改。现在 Opus 4.8 会自动规划任务 → 派发数百个并行子代理 → 让其他代理交叉验证 → 收敛后统一返回结果。
Anthropic 的说法是:「专为跨数十万行代码的迁移设计,从启动到合并。」但这个功能目前是 research preview,成本不低,每次运行前会弹确认。
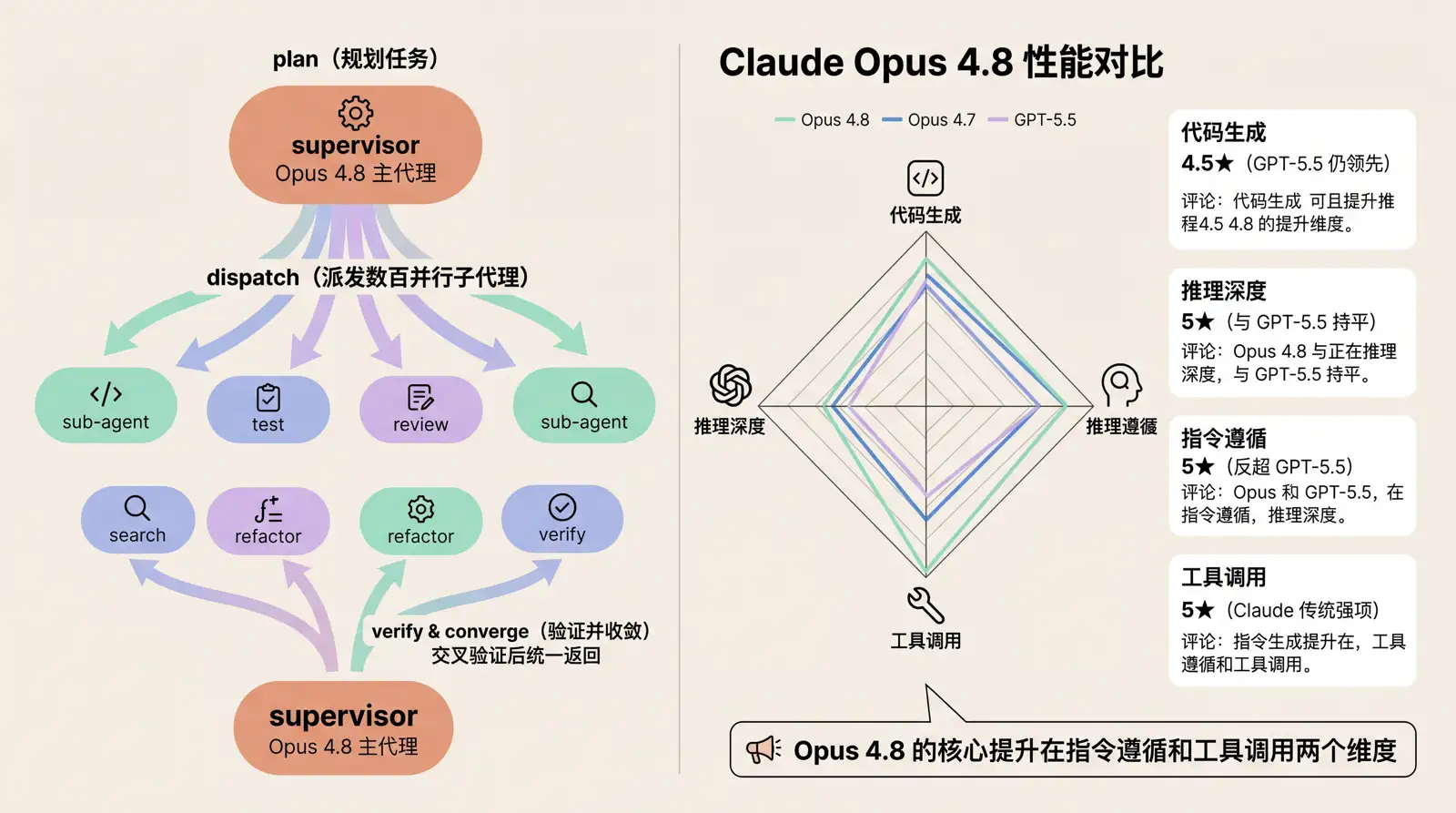
两种调用方式:
- 直接告诉 Claude 「create a workflow for this」
- 开启
ultracode模式,让 Claude 自动判断何时使用
3. Fast mode 降价 3 倍 + 默认 effort 降至 high
Opus 4.7 的 Fast mode 定价是 $30/$150 per 1 M tokens,贵得离谱。Opus 4.8 直接砍到 $10/$50,便宜了 3 倍,速度约 2.5 倍于标准端点。
同时默认 effort 从 xhigh 降到 high。Anthropic 的说法是:Opus 4.8 在 high 模式下消耗的 token 跟 Opus 4.7 在 xhigh 下差不多,但得分更高。
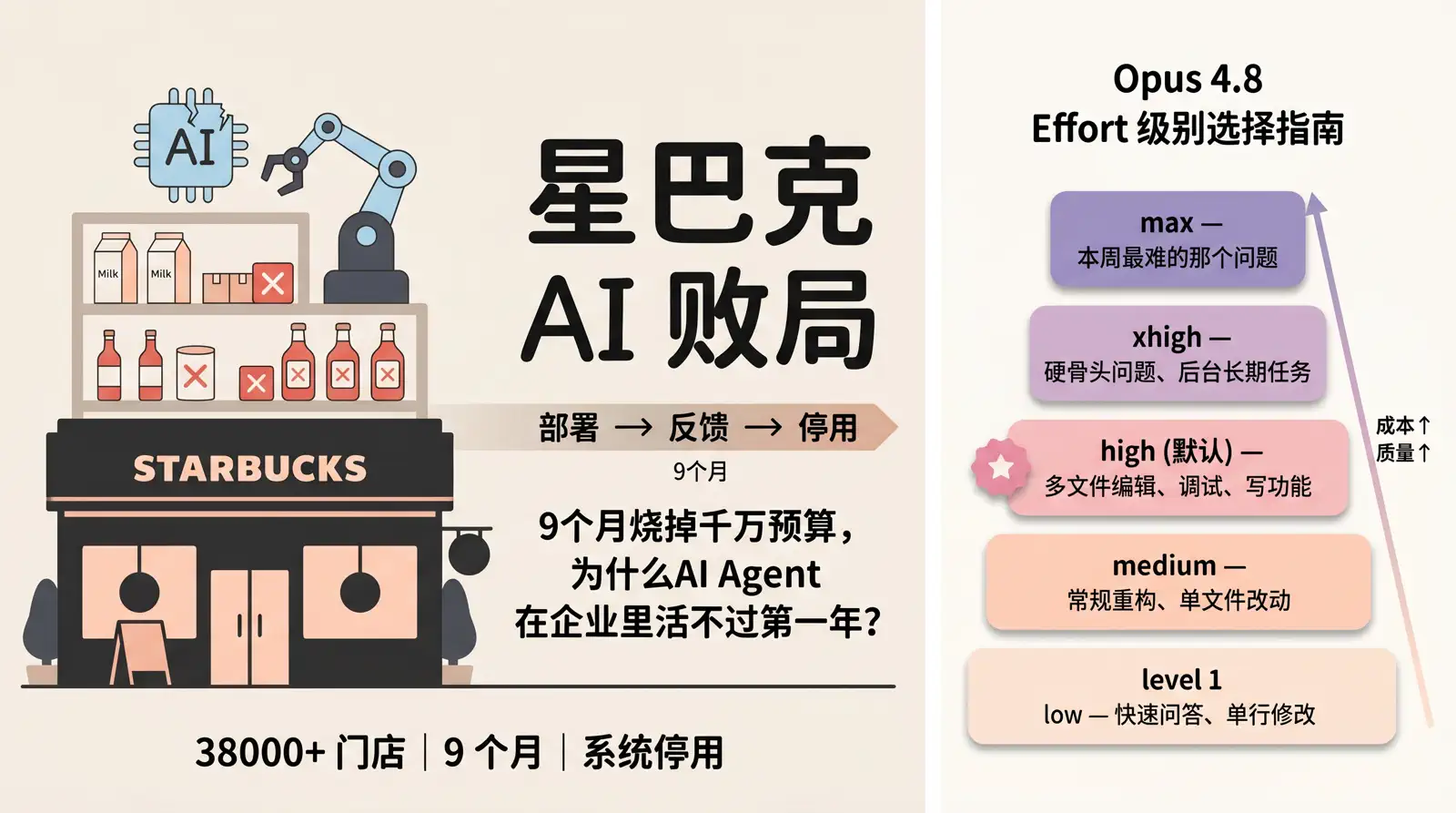
| Effort 级别 | 适用场景 |
|---|---|
low | 快速问答、单行修改 |
medium | 常规重构、单文件改动 |
high(默认) | 多文件编辑、调试、写功能 |
xhigh | 硬骨头问题、后台长期任务 |
max | 本周最难的那个问题 |
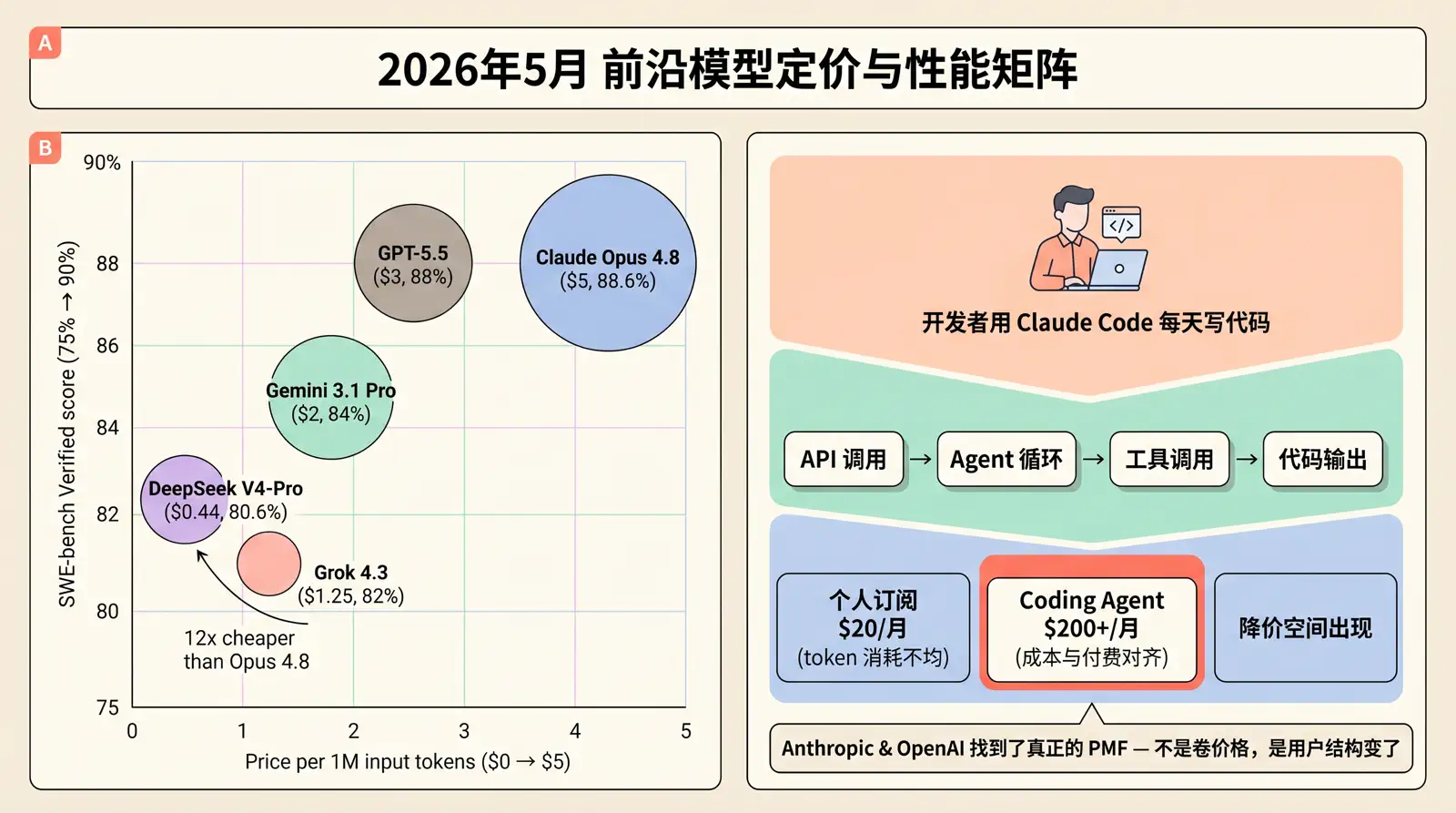
定价对比:值不值这个价?
标准定价完全不变,$5/$25 per 1 M tokens。但放在 2026 年 5 月的前沿模型定价表中,事情没那么简单:
| 模型 | 输入 ($/1 M) | 输出 ($/1 M) | SWE-bench Verified | 上下文窗口 |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 | $25 | 88.6% | 1 M |
| GPT-5.5 | ~$3 | ~$15 | ~88% | ~400 K |
| Gemini 3.1 Pro | $2/$4 | $12/$18 | — | 2 M+ |
| DeepSeek V 4-Pro | $0.435 | $0.87 | 80.6% | 128 K |
| Grok 4.3 | $1.25 | $2.50 | — | 1 M |
DeepSeek V 4-Pro 比 Opus 4.8 便宜 12 倍(输入)到 29 倍(输出),但 SWE-bench Pro 得分约 60%,差距约 9 个百分点。
结论很清楚: Opus 4.8 是市场上最贵的模型,但在 Agentic Coding 和 Computer Use 场景下,也是最好的模型。如果你的场景是高风险的代码生成(生产环境 bug 的代价 > 几十美元 token 费),Opus 4.8 是唯一正确的选择。
2026 年的最佳实践是分层架构:Opus 4.8 做计划和审查,DeepSeek V 4-Pro 或 Grok 4.3 做执行。
迁移建议:从 Opus 4.7 切换需要注意什么?
对于已在生产环境用 Opus 4.7 的团队,迁移只需改一行 model ID。但有三件事要提前知道:
1. Prompt 回归风险。 Opus 4.8 比 4.7 更「保守」——它会更多地说「我不确定」。如果你的下游解析器依赖模型输出自信的语气来判断结果质量,可能会误报。建议更新 prompt,让模型显式输出置信度标签,而不是依赖语气判断。
2. 上下文策略不变。 Anthropic API、Bedrock、Vertex AI 都支持 1 M tokens。Microsoft Foundry 仍限制在 200 K。
3. MCP 工具连接更可靠。 Claude Code 2.1 修复了一个长期 bug:MCP 服务器分页返回工具列表时不再丢失后续页的工具。如果你之前遇到过 agent 突然「忘记」某些工具的情况,这个问题已修复。
对开发者的影响
- 如果你在做 AI 编程助手评估: Opus 4.8 是目前 Agentic Coding 场景的第一选择,但价格让它不适合做大规模批量生成。你的架构应该是 Opus 4.8 做「规划+审查」,便宜模型做「执行」。
- 如果你用的是 Claude Code: 立即
claude update,然后/model opus。默认 effort 已降到high,日常用更便宜。遇到硬问题再切/effort xhigh。 - 如果你在等 Mythos: Anthropic 说「未来几周」全面开放。Mythos Preview 的网络安全能力远超 Opus 4.8,但用户面会更窄。对大多数开发者来说,Opus 4.8 就是未来几个月的主力。
FAQ
Opus 4.8 和 GPT-5.5 比,到底哪个更好?
看场景。Agentic coding(SWE-bench Pro 69.2 vs 58.6)和知识工作(GDPval Elo 1890 vs 1769),Opus 4.8 领先。纯终端自动化(Terminal-Bench 78.2 vs 74.6),GPT-5.5 仍然更好。如果你主要用 AI 写代码,Opus 4.8 是目前最强的选择。
我是个人开发者,值得从 Opus 4.7 升级吗?
值得。标准价格不变,Fast mode 还便宜了 3 倍。默认 effort 降到 high 意味着日常使用成本可能更低。唯一需要适应的是它会更频繁地说「我不确定」——但这其实是好事,省得你事后 debug。
Opus 4.8 什么时候能用上?
现在就可以。Claude.ai、Claude Code、API、Amazon Bedrock、Google Vertex AI、Microsoft Foundry、GitHub Copilot 都已支持。API 端 model ID 是 claude-opus-4-8。
开源模型有没有能打 Opus 4.8 的?
暂时没有。DeepSeek V 4-Pro 在编程上最接近(SWE-bench 约 60%),Qwen 3.7 Max 在数学推理上很强。但 Agentic coding + Computer Use 的综合能力,还没有开源模型能对标 Opus 4.8。考虑到 DeepSeek 的演进速度,这个差距可能在 3-6 个月内缩小。
参考来源
- Anthropic, Introducing Claude Opus 4.8, 2026-05-28, anthropic.com
- ComputingForGeeks, Claude Opus 4.8: Features, Benchmarks, 2026-05-28
- Codersera, Claude Opus 4.8 Launch Guide: Benchmarks & Pricing, 2026-05-28
- CNBC, Anthropic tops OpenAI as most valuable AI startup, 2026-05-28

NVIDIA N1/N1X Computex 2026 登场:ARM 芯片宣告 AI PC 时代到来
NVIDIA Computex 2026 发生了什么?2026年6月1日上午11点(台北时间),NVIDIA CEO Jensen Huang在Computex主题演讲中正式发布了首款ARM架构笔记本芯片N1和N1X。这不只是一次芯片发布——它标志着NVIDIA正式进入Windows on ARM PC市场,直接挑战Qualcomm Snapdragon X Elite和Apple M系列。N1X旗舰芯片配备20核ARM CPU、6144 CUDA核心和Blackwell GPU架构。N1定位面向创意专业人士。两款芯片都内置AI加速引擎,支持本地运行大语言模型。ASUS已确认ProArt系列将搭载N1芯片。Microsoft Surface负责人Pavan Davuluri暗示"为开发者准备了新东西"。Dell XPS出现在Computex展示材料中。最详细的信息来自Lenovo:Legion 7配245W电源适配器,IdeaPad Slim 5和Yoga Pro 7多型号确认。这意味着从轻薄本到游戏本全产品线覆盖。N1X芯片的技术规格有多强?N1X采用20核ARM v9架构CPU,配合6144 CUDA核心的Blackwell GPU。与竞品对比:Qualcomm Snapdragon X Elite为12核Oryon CPU,Apple M4 Pro为14核CPU+20核GPU。N1X在GPU规模上遥遥领先,这也是NVIDIA的传统优势。245W电源适配器配置(Lenovo Legion 7)表明N1X定位在高性能游戏和创作本市场。相比之下Apple M4 Max的整机功耗约60W。NVIDIA走的是一条高性能路线,而非极致能效。N1X支持本地运行70亿参数级LLM,AI算力约45 TOPS。这对开发者意味着可以在本地完成代码辅助、文档生成等AI任务,无需云端调用。NVIDIA ACE数字人技术栈同时GA意味着什么?NVIDIA同时宣布ACE(Avatar...
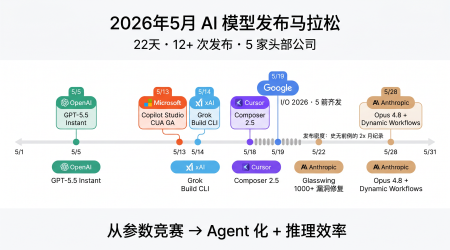
22 天 10+ 款前沿发布:2026 年 5 月 AI 模型马拉松全景解读
2026年5月是AI史上最密集发布月:GPT-5.5 Instant、Gemini 3.5 Flash、Claude Opus 4.8等10+款前沿发布全景解读。从参数竞赛到Agent化范式转变。

Google I/O 2026 复盘:Gemini 月活 9 亿、全栈 Agent 化、世界模型,Google 用「生态反击」回应了所有人
如果你这周只看了一场发布会,你可能会以为 Anthropic 和 OpenAI 是这个行业唯一的两个玩家。
5 月 20 日 Google I/O 把这种印象彻底打碎了。Pichai 开场用了不到 20 分钟甩出一组数字:Gemini 月活 9 亿(一年前是 4 亿),覆盖 230 个国家 70 种语言,Google Search 的 AI Mode 查询量每季度翻倍。然后才是产品:Gemini 3.5 Flash、Omni 世界模型、Spark 跨应用 Agent、Agent Payments Protocol。
但 Google I/O 2026 真正值得关注的东西不是单一产品,而是一个模式:Google 在用生态宽度打...

Claude Code 生态大爆发:从 v2.1.152 更新到 GitHub 全栈工具链,开发者正在给 AI 疯狂装「外挂」
如果你今天打开 GitHub Trending,会看到一副罕见的景象:前 10 名中至少有 4 个项目直接与 Claude Code 相关——ECC(19.4 万星)、claude-mem(7.8 万星)、taste-skill(2.1 万星)、Anthropic 官方的 knowledge-work-plugins(1.6 万星)。同一天,Claude Code v2.1.152 发布了。
这不是巧合。Claude Code 正在从一个「AI 编程工具」变成一个「AI 编程平台」,而开发者社区的狂热反应是最诚实的信号灯。
v2.1.152:三个看似小、实则深远的改动
先看官方更新。v2.1.152 的 changelog 不算长,但有三项改动直接指向了 Claude Code 的产品方向:
/code-review --fix 落地。之前 code review 只出报告,看完了你得自己改。现在 --fix 标志会把审查建议直接应用到工作目录。这意味着 code review 从「顾问」变成了「执行者」。
Skill 的...

AI 视频生产三连击:Runway Luxo + Gemini Omni + Kling 同时跨过「能用」门槛
如果你对 AI 视频的印象还停留在「那些有点诡异的六指人类和违反物理定律的物体运动」,今天有三个独立信号在告诉你:可以更新认知了。
Runway Luxo:跨越恐怖谷
Runway 今天发布了 Project Luxo 的研究结果,核心结论只有一句话:AI 生成视频已经跨过了恐怖谷。
他们做了什么?向创意行业的从业者展示了包括 AI 短片《The Rogue》和广告样片在内的作品,然后评估观众的反应。结果是:观众开始关注故事本身,而不是技术瑕疵。
更有意思的是生产效率数据:所有作品都由单人团队制作,耗时从 3 周到 4 小时不等。用 Runway 的话说:「当技术足够好以至于『隐形』,观众沉浸于故事而非技术时,就意味着跨越。」
这个判断标准其实很聪明——它不是用 PSNR 或 FVD 这些技术指标来证明 AI 视频「变好了」,而是用观众的行为数据。当观众不再在弹幕里刷「AI 生成的吧」,AI 视频就真的成熟了。
Gemini Omni:不只是生成,而是「拍摄」
同一天,Google 官方发布了 Gemini Omni 的视频提示词指南。五条技巧,每一条都值得细读:
利用模型已有的现实世界知识。Gemini Omni 的训练数据包含了大量现实世界的视觉信息,你不需要描述「一辆红色的汽车长什么样」,直接说「一辆红色特斯拉 Model 3 在太平洋海岸公路上行驶」就行。
精确控制文本渲染。视频中的文字排版一直是 AI 视频的弱项,Gemini Omni 在这方面做了针对性优化,支持指定字体、位置和动效。
使用专业镜头指令。推拉摇移、景深、构图——用电影摄影师的术语来写提示词,而不是「拍得好看一点」。
迭代编辑而非重拍。不需要因为一个细节不满意就重新生成整个视频。可以像改代码一样在上一版基础上修改。
直接调整角色的动作节奏或情绪。对于叙事类内容,这个能力意味着你不需要重新设计角色动画,只需要告诉模型「让她走得更快一点」或「表情更紧张」。
这些技巧看起来简单,但背后反映的是...

「选择保持人性」— Ethan Mollick 最新长文:当 AI 能写出一切,什么内容还值得人类亲自生产?
Ethan Mollick 是沃顿商学院教授,也是 AI 领域最受关注的博主之一(One Useful Thing)。他今天发表了一篇新文章,标题直接得刺眼——《Choosing to Stay Human》(选择保持人性)。
你在社交媒体上看到的东西,可能是 AI 写的
Mollick 开篇就抛出了一个问题:
如果你现在打开你最喜欢的社交媒体,你会发现上面的帖子开始看起来惊人地相似。
不只是帖子。评论区越来越多的 AI 生成回复,学术论文、纽约时报观点文章、文学奖投稿中 AI 撰写的比例在快速攀升。Mollick 直接拿教育、咨询和最近文学奖争议三个领域做切片,追问一个问题:当 AI 可以大规模生产「看起来像人写的内容」,人类创作的独特性到底在哪里?
AI 让内容走向「均值回归」
Mollick 的核心观察是:AI 生成的内容在统计上会趋向于「最安全、最平均」的表达。不是故意平庸,而是训练数据和概率分布的自然结果。
类似的事在搜索引擎时代发生过一次。SEO 让全网的网页标题和开头段落都变成了同一套模板。AI 把这个过程加速了几个数量级。
对于内容创作者来说,这个判断隐含一个重要的结论:未来内容的价值将不再取决于「写得好不好」,而是取决于「能不能写出 AI 写不出的东西」。后者不是指技术层面(AI 当然能模仿任何风格),而是指信息来源的独特性和观点的不可复制性。
什么应该交给 AI,什么必须保留?
Mollick 的文章并不是「AI 有害论」。他的态度更接近一种清醒的分类学——哪些工作可以放心交给 AI,哪些必须由人类亲自完成:
可交给 AI:标准化产出、模板化内容、信息聚合、例行报告
应保留人类:需要真实体验支撑的判断、第一手的实验观察、带有个人风险承担的洞见、不可复现的创造性时刻
Mollick 文章中最有力的一句话也许是:「社交媒体的帖子看起来越来越像彼此。这不仅是审美问题——当你无法区分原创和复制品时,你就会停止相信任何东西。」
这句话恰好点中了 AI 内容泛滥的真正代价:不是内容质量下降,而是信任体系的瓦解。
对中文内容生态的延伸思考
Mollick 讨论的是英文互联网,但中文内容生态面临的挑战只多不少。
公众号、小红书、知乎等平台上的 AI 生成内容比例正在快速上升。区别在于,中文 AI...

ECC 开源项目深度拆解:19 万星的 Agent 性能调校系统,给 AI 编程装上「变速箱」
如果你用过 Claude Code 或 Codex CLI 写代码,大概率遇到过这种情况:agent 为一个简单功能读了 15 个不相关的文件,调用了 8 个不需要的工具,烧掉了一大堆 token,最后代码还没写好。
ECC 要解决的就是这个问题。
ECC 是什么?
ECC 的全称很长——「The agent harness performance optimization system」(Agent 执行层性能优化系统)。简单说,它像是给 AI 编程 agent 装了一个「变速箱」和「刹车」,告诉 agent:这个场景下你只需要看这些文件、用这些工具、以这种节奏工作。
它的核心模块包括 5 个:
Skills。定义 agent 在特定场景下使用的能力清单。比如「debug 模式」下 agent 可以读日志、跑测试、查看 git diff;「refactor 模式」下 agent 可以用 replace_content...
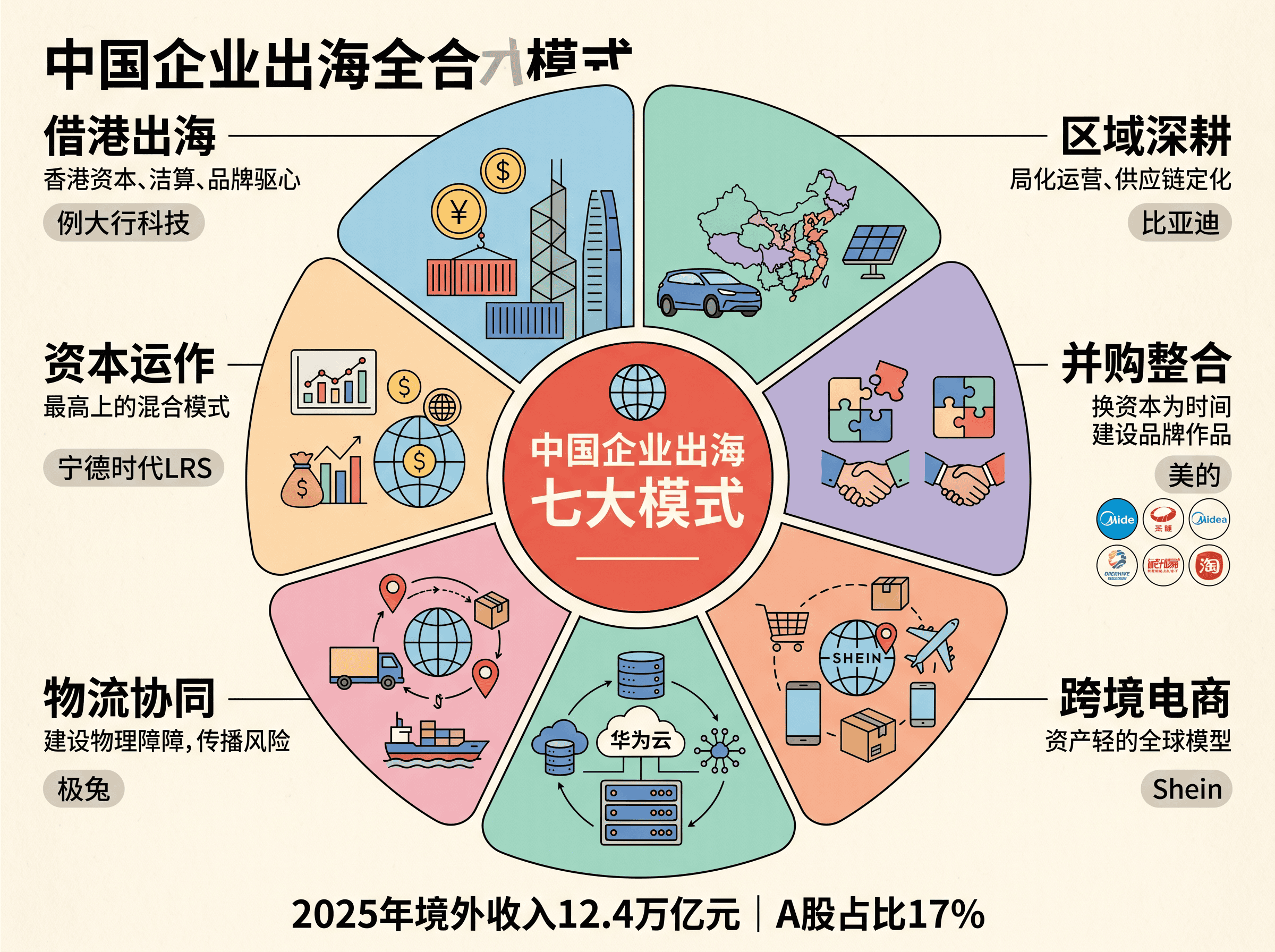
中国企业出海七大模式全解析:2025-2026年全球化路径与战略选择
2025年A股上市公司境外收入首次突破12.4万亿元,占比近17%。本文拆解借港出海、区域深耕、并购整合、跨境电商、技术赋能、物流协同、资本运作七大出海模式,结合比亚迪、海尔、美的等最新案例,提供出海模式决策框架。

72小时内,AI 行业换了剧本:Anthropic 首次盈利,OpenAI 秘密申请史上最大 IPO
5 月 20 日到 22 日。72 小时。
周三,Anthropic 向投资人披露:Q2 预计收入 $109 亿,首次运营利润 $5.59 亿。周四,消息传出 OpenAI 准备密交 IPO 申请。周五,申请正式提交——目标估值 $1 万亿,Goldman Sachs 和 Morgan Stanley 联席承销。
再加上 SpaceX S-1 披露的 Anthropic $450 亿算力合同——72 小时内爆出的信息量,比过去三个月加起来都多。但重点不在于数字有多大。重点在于这些数字同时出现时,拼出的图景和之前所有人以为的都不一样。
以前的主流叙事是:AI 行业在烧钱换规模,盈利遥遥无期。这 72 小时把这个叙事翻了过来。
Key Takeaways
– Anthropic Q2 预计收入 $109 亿(Q1...