
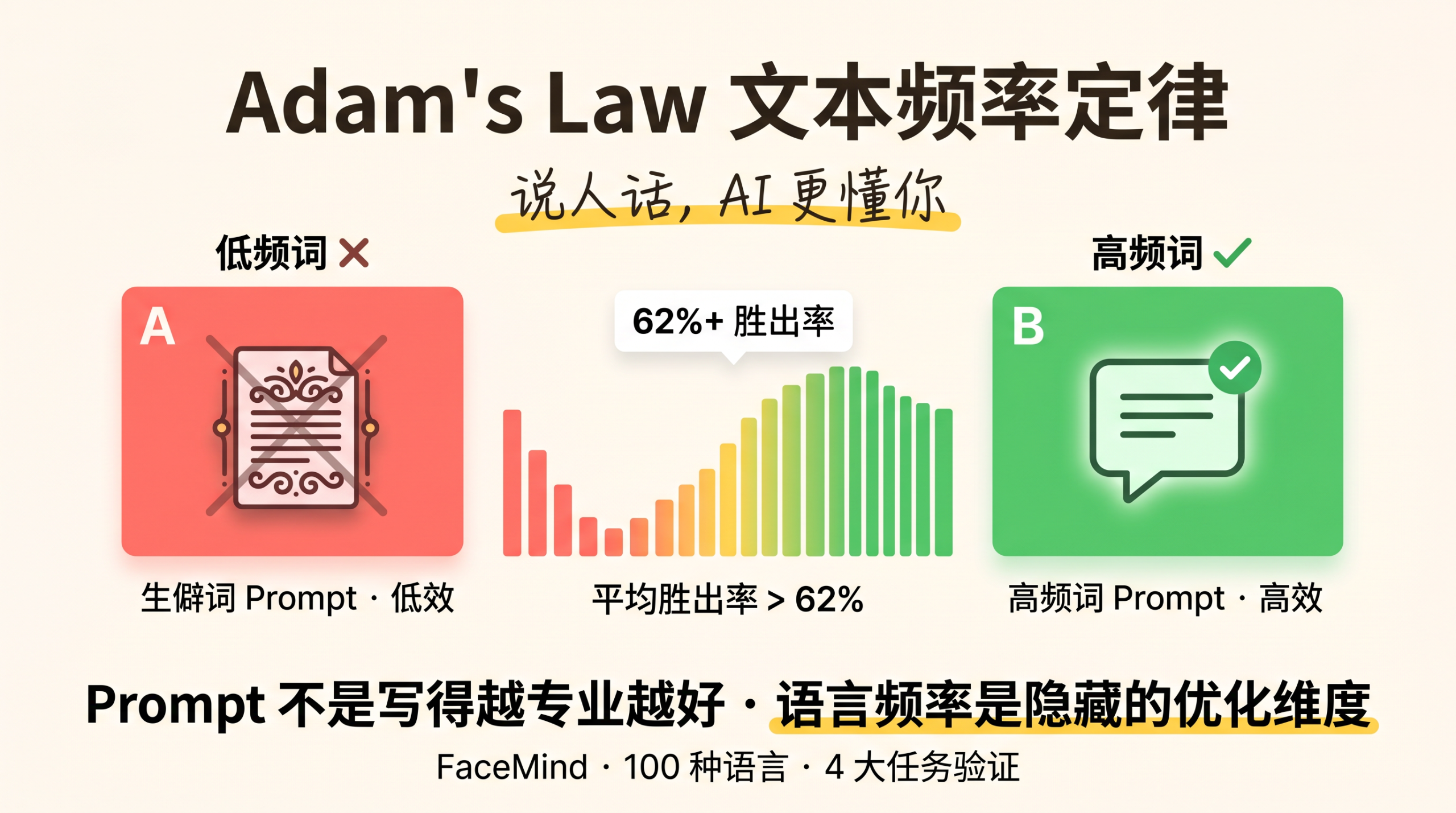
Marketing Skills — 37K 星 AI Agent 营销技能库:CRO、SEO、文案、增长工程一站式 Agent 工具包
一句话结论:Marketing Skills 是 Corey Haines 构建的一个开源 AI Agent 营销技能库,已在 GitHub 获得 37,000+ Stars。它包含 36 个结构化营销技能,覆盖转化率优化(CRO)、文案写作、SEO 审计、数据分析、增长工程等领域,让 AI 编码 Agent 变身专业营销顾问。
项目介绍
Marketing Skills 是一个遵循 Agent Skills 规范 的技能集合。每个技能是一个 Markdown 文件,给 AI Agent 注入特定营销任务的专业知识和结构化工作流。当你在项目中添加这些技能后,Agent 能识别你正在做营销任务,自动应用正确的框架和最佳实践。
作者 Corey Haines 是 Conversion Factory 和...
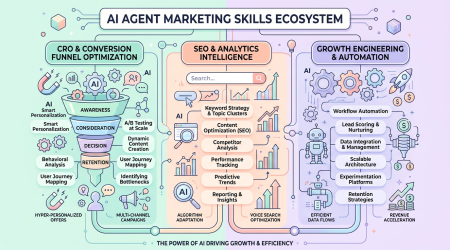
AI Job Search — 7K 星 Claude Code 求职框架:让 AI Agent 帮你投简历、写求职信、模拟面试
一句话结论:AI Job Search 是一个基于 Claude Code 的 AI 求职框架,在 GitHub 上已获得 7,000+ Stars。它把 Claude Code 变成一个全能求职助手:自动评估岗位匹配度、定制简历、写 Cover Letter、准备面试。TypeScript 开发,MIT 开源。
项目介绍
AI Job Search 由丹麦开发者 Mads Lorentzen 创建,核心思路是:把求职变成一个结构化的、AI 可执行的流水线。你只需填写个人资料(CV、技能、经历),Claude Code 会自动完成后续所有步骤。
核心工作流(自我画像→岗位匹配评估→起草-审查申请流水线)是语言和国家无关的。内置的丹麦求职门户技能(Jobindex、Jobnet 等)可以替换为你当地的求职网站。项目还提供了 /add-portal 命令自动生成新求职门户的搜索技能。
核心功能
自我画像:填写 CV、技能、工作偏好后,Agent 自动建立你的职业画像
岗位匹配评估:Agent 分析岗位描述,评估匹配度,给出申请建议
简历定制:根据目标岗位自动调整简历重点和关键词
Cover Letter 生成:起草-审查双 Agent 流水线,确保质量
面试准备:基于岗位描述生成常见问题和回答建议
LinkedIn 全球搜索:通过公开...
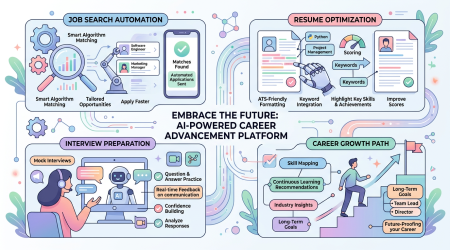
Agent Skills — Addy Osmani 开源的 AI 编码 Agent 24 技能包:从 Spec 到 Ship 全生命周期工程规范
一句话结论:Agent Skills 是 Google Chrome 工程总监 Addy Osmani 开源的生产级 AI 编码 Agent 技能包,24 个技能覆盖 Define→Plan→Build→Verify→Review→Ship 完整开发周期。支持 Claude Code、Cursor、Codex、Copilot 等 70+ 工具。将 Google 工程文化的最佳实践编码为 Agent 可执行的结构化工作流。
项目介绍
AI 编码 Agent 默认走最短路径——跳过 Spec、跳过测试、跳过安全审查。Agent Skills 给 Agent 注入了资深工程师的工程纪律:什么时候写 Spec、测试什么、怎么审查、什么时候上线。这不是通用 Prompt,而是经过 Google 工程文化验证的、结构化的、有明确验证标准的工程工作流。
每个技能包含:流程步骤、验证检查点、反借口表(阻止 Agent 跳过步骤)、红线标记。设计理念来自
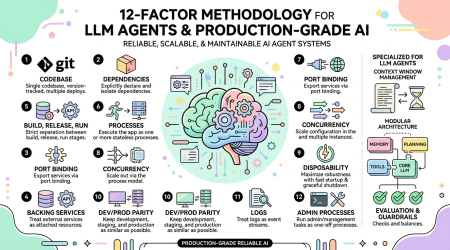
12-Factor Agents — 构建生产级 LLM 应用的 12 条原则:从原型到可靠产品的工程方法论
一句话结论:12-Factor Agents 是 HumanLayer 提出的构建生产级 LLM 应用的 12 条工程原则,受 12-Factor App 方法论启发。它回答了一个核心问题:什么原则能让我们构建的 LLM 应用真正达到可以交付给生产客户的质量标准?
项目介绍
作者 Dexter 在构建 AI Agent 产品时发现一个普遍问题:大多数 Agent 项目能达到 70-80% 的质量,但突破 80% 进入生产级别需要深入了解框架内部。他提炼了 12 条原则,帮助开发者从一开始就用正确的方式构建可靠的 LLM 应用。
核心洞察:即使 LLM 持续指数级增长,依然存在核心工程技巧让 LLM 应用更可靠、更可扩展、更易维护。最关键的是——你不需要全盘重写来采用 Agent 架构,可以逐步将 Agent 的模块化概念融入现有产品。
12 条原则
自然语言优先 — 用自然语言定义...
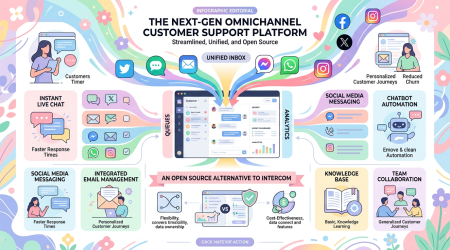
Chatwoot — 30K 星开源客服平台:自托管替代 Intercom/Zendesk,支持全渠道 + AI Agent
一句话结论:Chatwoot 是 GitHub 上 30,000+ Stars 的开源客服平台,自托管替代 Intercom 和 Zendesk。支持网站实时聊天、邮件、WhatsApp、Facebook 等全渠道收件箱,内置 AI 助手和知识库。Ruby on Rails 开发,数据完全私有。
项目介绍
Chatwoot 是现代开源客服支持平台,为需要完全控制客户数据的企业设计。它将所有客户对话集中到一个强大的收件箱,无论客户从哪里联系你。支持 网站实时聊天、邮件、Facebook、Instagram、Twitter、WhatsApp、Telegram、Line、SMS 等渠道。
核心优势:完全自托管,数据归你所有。适合有合规要求(GDPR、HIPAA)或不想把客户数据交给第三方 SaaS 的企业。
核心功能
全渠道收件箱:网站、邮件、社交、即时通讯,一个界面管理所有对话
AI 助手:自动回复、意图识别、情感分析、对话摘要
知识库:内置帮助中心,支持多语言
联系人管理:客户画像、交互历史、自定义字段
团队协作:对话分配、内部备注、预设回复(Canned Responses)
自动化:基于规则的自动分配、标签、触发器
API 和 Webhook:完整 REST API,支持自定义集成
移动端:React Native 构建的 iOS/Android App
安装方式
# Docker 一键部署(推荐)
docker run -p 3000:3000 chatwoot/chatwoot
# 手动安装(Ubuntu)
git clone https://github.com/chatwoot/chatwoot.git
cd...
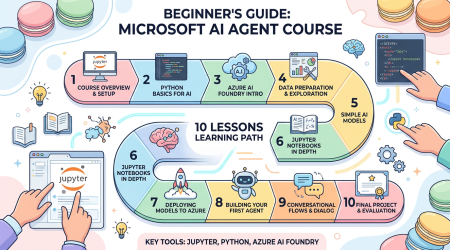
AI Agents for Beginners — 微软官方 AI Agent 入门课程:10 节课从概念到代码
一句话结论:AI Agents for Beginners 是微软官方的 10 节 AI Agent 入门课程,使用 Microsoft Agent Framework (MAF) 和 Azure AI Foundry,从概念到代码带你构建第一个 AI Agent。支持中文等多语言,免费开源。
项目介绍
这是微软官方出品的 AI Agent 入门课程,在 GitHub 上开源。每节课包含 视频讲解 + 文字教程 + Python 代码示例 (Jupyter Notebook),使用 Microsoft Agent Framework 和 Azure AI Foundry...
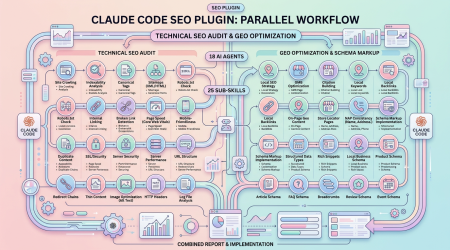
Claude SEO — 11K 星 Claude Code SEO 插件:25 子技能 + 18 专业 Agent 并行审计
一句话结论:Claude SEO 是一个开源的 Claude Code SEO 分析插件,已在 GitHub 获得 11,000+ Stars。它拥有 25 个子技能和 18 个专业 Agent,可并行执行技术 SEO、E-E-A-T 评分、Schema.org 标记、GEO/AEO(AI 搜索优化)、本地 SEO、电商 SEO、国际 SEO 等全方位审计。MIT 开源,完全离线可用。
项目介绍
Claude SEO 由 Daniel Agrici 开发,是目前功能最全面的开源 SEO 分析工具。它遵循 Google 官方 AI 优化指南 和 2025 年...
Pixelle-Video — 开源 AI 全自动短视频引擎:输入主题,3 分钟出视频
一句话结论:Pixelle-Video 是一个开源的 AI 全自动短视频生成引擎,输入一个主题即可自动完成脚本撰写、AI 配图、语音合成、背景音乐和一键合成视频。支持多种 AI 模型和 TTS 方案,完全免费方案仅需本地 Ollama + ComfyUI。中文友好。
项目介绍
Pixelle-Video 由 ATH-MaaS 团队开发,是一个"输入主题,3 分钟出视频"的全自动 AI 短视频引擎。不需要视频编辑经验,不需要复杂配置。基于 ComfyUI 架构,支持预设工作流和自定义能力扩展。
核心功能
全自动生成:输入主题 → 自动出完整视频
AI 智能文案:基于主题自动生成解说词
AI 配图/视频:每句解说词配精美 AI 插图
AI 语音合成:支持 Edge-TTS、Index-TTS 等主流方案
背景音乐:自动添加 BGM 增强氛围
多种视觉风格:多个模板打造独特视频风格
灵活尺寸:支持竖屏、横屏等多种视频尺寸
多 AI 模型:GPT、千问、DeepSeek、Ollama 等
成本方案
方案配置成本完全免费Ollama (本地) + 本地 ComfyUI$0推荐方案千问 LLM +...
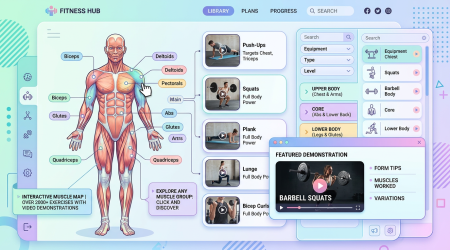
MuscleWiki — 2000+ 动作交互式健身库:点击肌肉,秒查训练动作
一句话结论:MuscleWiki 是一个免费的交互式健身动作库,收录 2,000+ 个动作和 7,500+ 个视频演示。通过交互式肌肉地图,点击任意肌肉即可看到针对训练动作。提供免费 API,适合健身 App 开发者集成。
项目介绍
MuscleWiki 以独特的交互式肌肉地图为核心体验。人体模型上标注了 45 个肌肉群,点击任意肌肉即可显示该部位的针对性训练动作,每个动作都配有视频演示和分步文字说明。是目前互联网上最直观的健身动作查询工具。
核心功能
交互式肌肉地图:45 个肌肉群可视化标注,点击即查
2,000+ 动作库:覆盖全身所有肌群
7,500+ 视频演示:专业动作教学视频
分步文字指南:每个动作的详细执行说明
免费 API:供开发者集成到健身 App 中
移动端适配:响应式设计,手机浏览器完美体验
API 使用
# 获取所有动作
curl https://api.musclewiki.com/v1/exercises
# 按肌肉群筛选
curl https://api.musclewiki.com/v1/exercises?muscle=biceps
# 完整 API 文档见
# https://api.musclewiki.com/documentation
适用场景
健身 App:嵌入动作教学视频和文字指南
个人训练:查询不熟悉的动作正确做法
教练教学:快速展示动作给学生看
内容创作:健身文章和视频的参考资料
FAQ
MuscleWiki 免费吗?
网站完全免费。API 有免费层,适合个人项目和中小型应用。商业大规模使用需查看 API 定价。
和 YouTube 健身视频有什么区别?
MuscleWiki 的独特优势是按肌肉定位。你不知道动作名字,但你">>知道想练哪个部位——点击肌肉就能找到所有针对该部位的动作。
相关链接
MuscleWiki 官网
MuscleWiki API
Exercises...
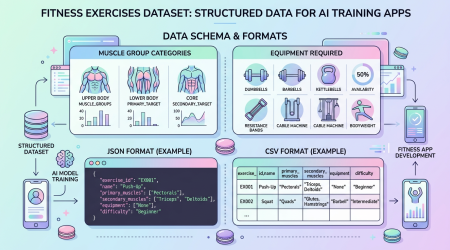
Exercises Dataset — 433 个健身动作开源数据集:为你的健身 App 和 AI 模型提供结构化数据
Exercises Dataset 提供 433 个健身动作的结构化数据,并整合 MuscleWiki 动作演示与 DAREBEE 免费训练计划,适合健身 App、AI 模型和个人训练参考。