
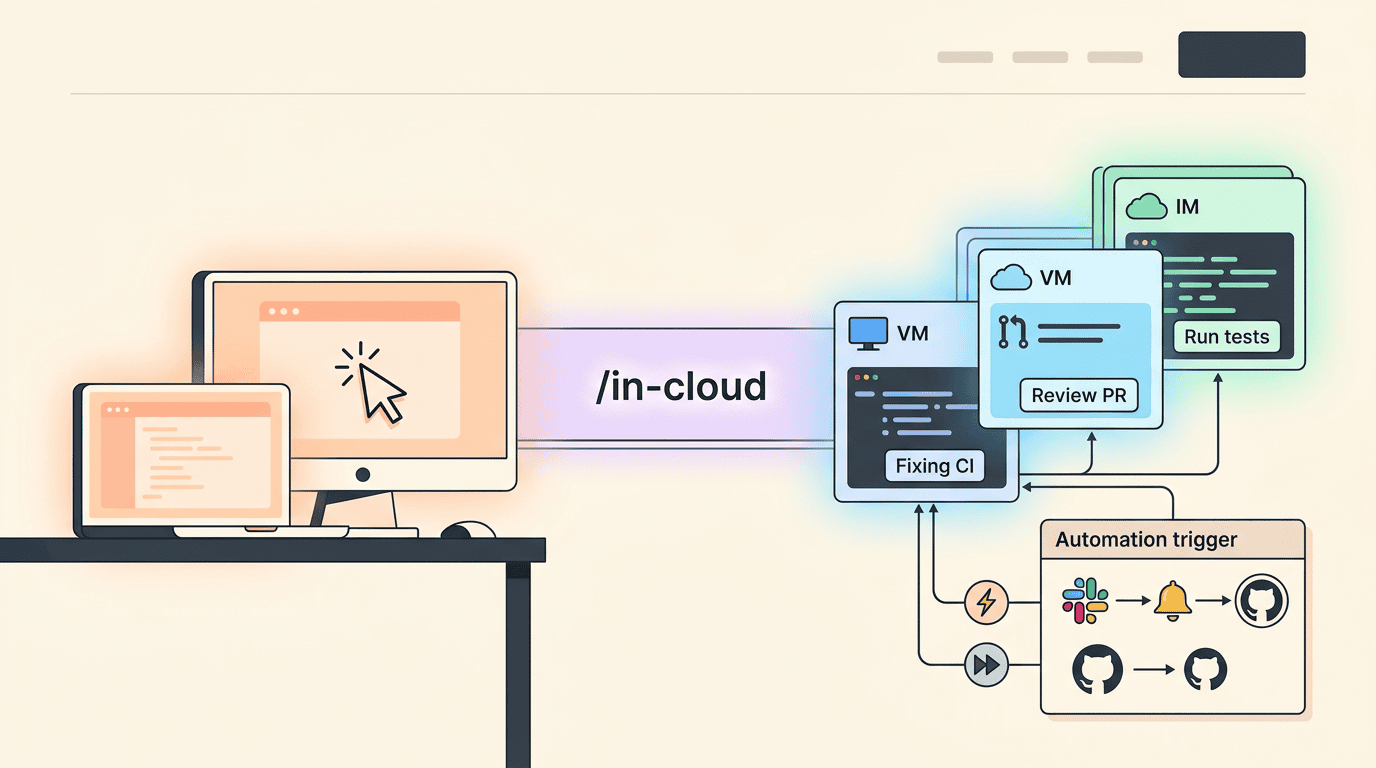
Cursor 10天3版:编程Agent正在长出「双手」
Cursor 6月5日到18日密集发布3个版本:3.7把Agent搬上云端(/in-cloud、/babysit),3.8教会Agent自动化(/automate技能、6种新触发器)。编程Agent正从帮人写代码进化到替人完成开发闭环。
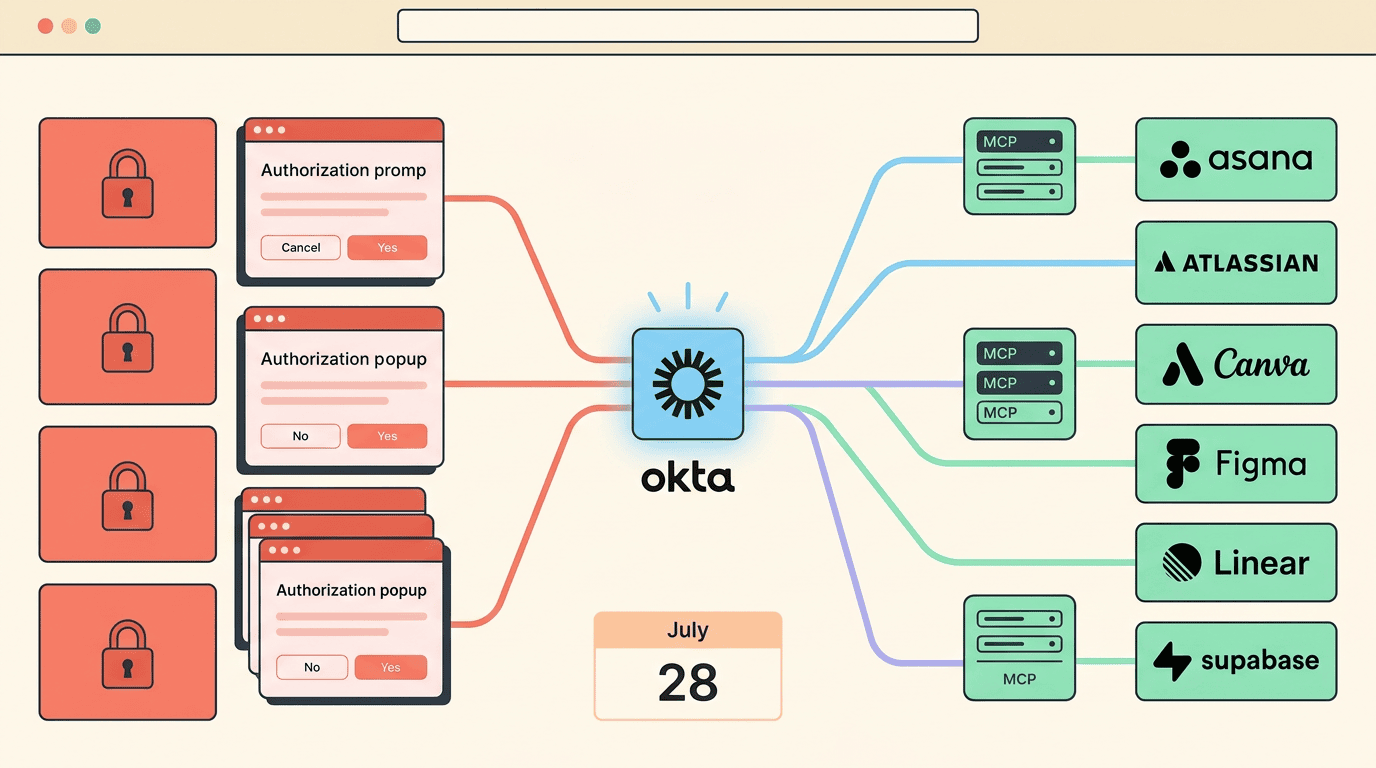
MCP企业授权稳定版发布:Agent协议终于拿到了企业入场券
6月18日MCP企业授权(EMA)正式稳定,Okta首发支持,零触控OAuth补齐企业最后一块拼图。7月28日史上最大协议更新进入40天倒计时——从会话驱动到无状态、MCP Apps交互式UI、Tasks扩展。
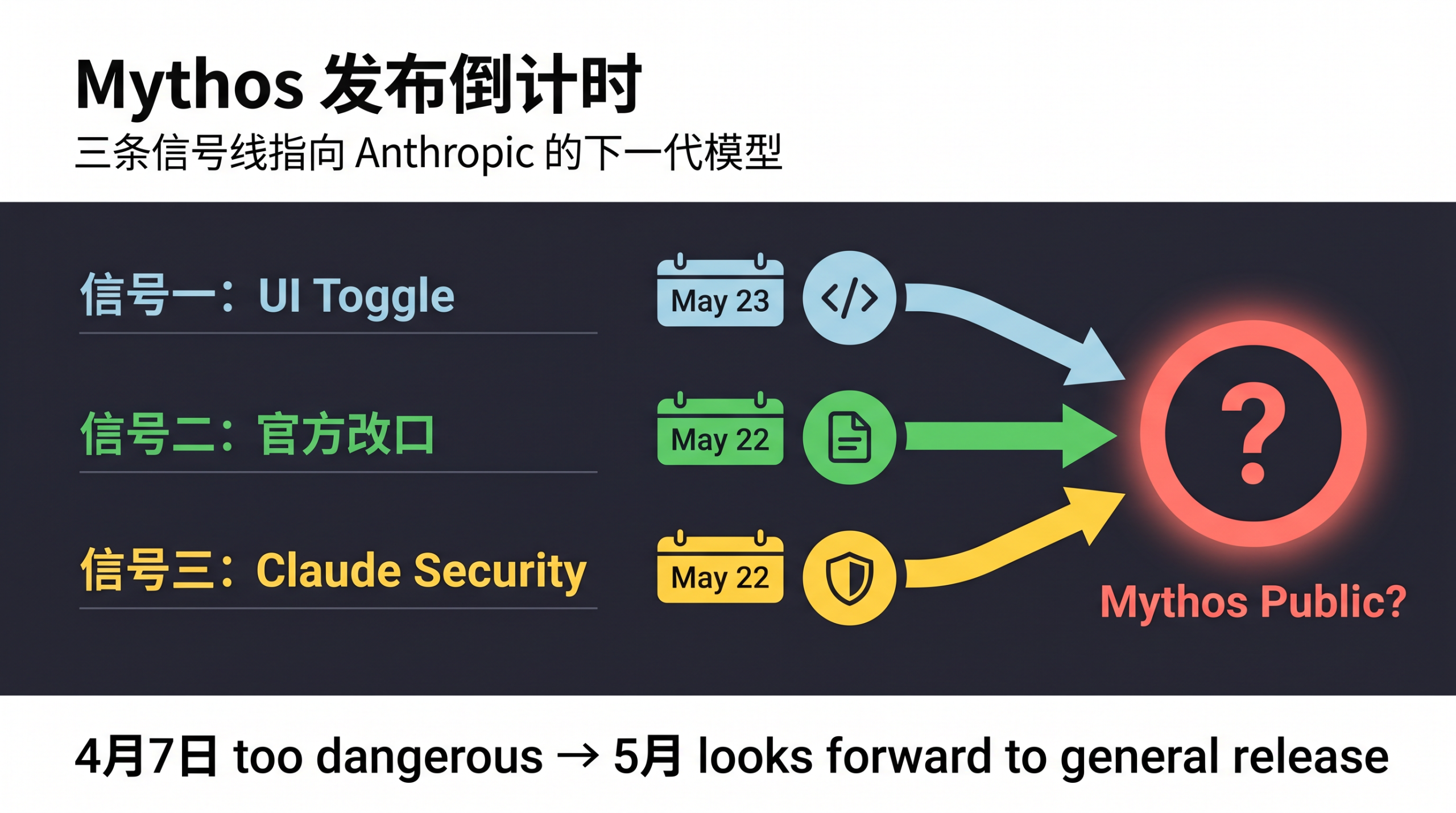
Claude Mythos 公开发布倒计时:「三线信号」解读 Anthropic 的「核武器」释放计划
三条信号线如何拼出Mythos发布图景? 2026年5月最后一周,三件事同时发生。信号一:5月23日Claude Code公共界面短暂出现「Mythos 1」toggle,源代码中新增引用串。信号二:5月22日Anthropic官宣Gl……

Anthropic NLA 深度解读:可解释性突破首次「读取」Claude 内心,发现 26% 的测试感知
Anthropic NLA到底发现了什么? Anthropic在2026年5月底公布了NLA(Natural Language Autoencoders)。这是一种能直接读取AI模型内部激活模式(activations)并翻译成自然语言……
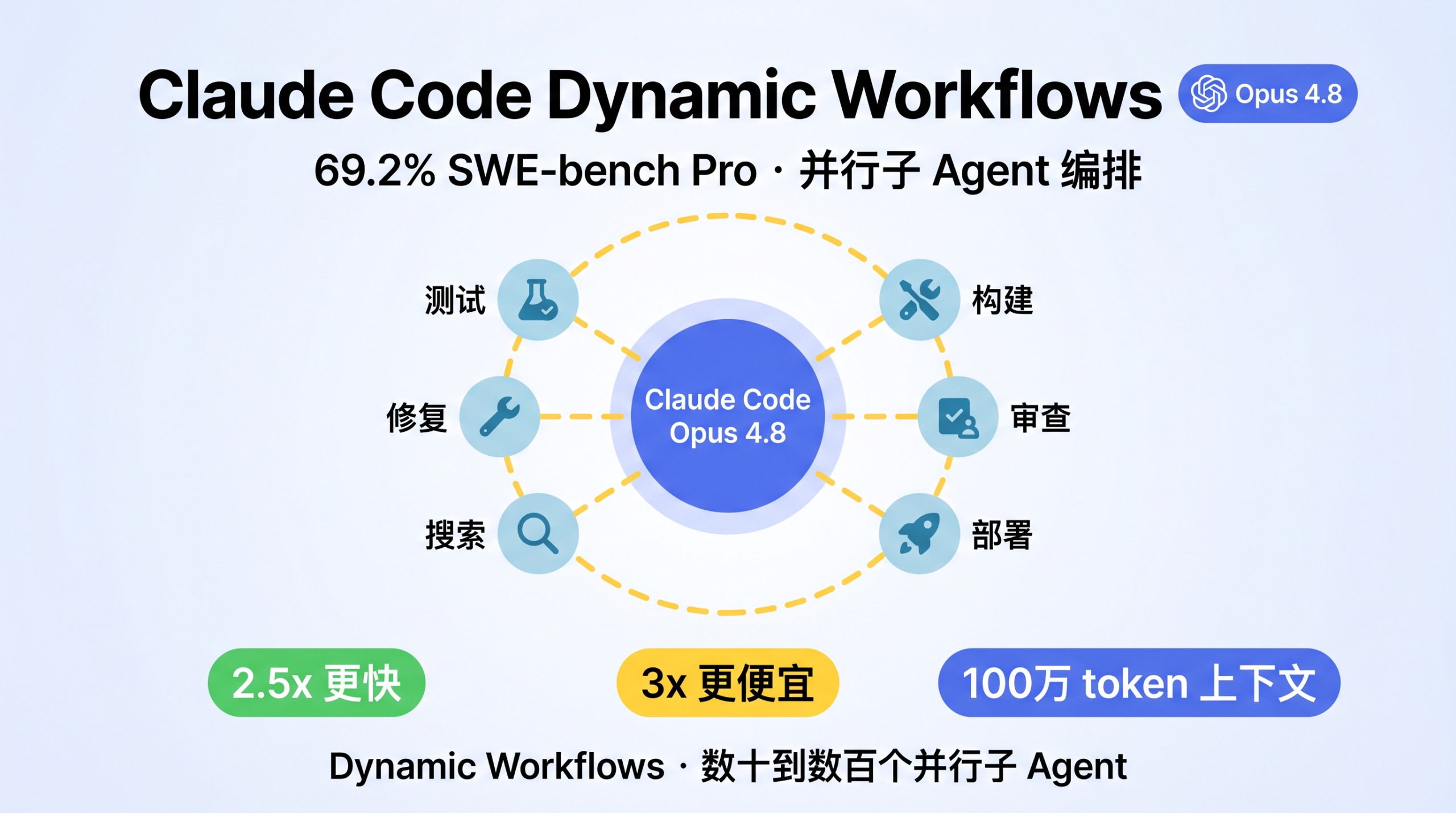
Claude Code Dynamic Workflows 实战:Opus 4.8 与 Ultracode 模式详解
实测 Claude Opus 4.8 SWE-bench Pro 69.2%、Dynamic Workflows 并行子 Agent 编排、Ultracode 模式配置。Fast Mode 快 2.5 倍、成本降 67%,附命令示例。