

Satya Nadella:没有生态的前沿不稳定——人力资本与 Token 资本如何复合增长
微软 CEO Satya Nadella 提出人力资本与 Token 资本复合增长理论。企业应能替换底层模型而不丢失专家知识。

谷歌安全主管愤而辞职,AI 军事化正在撕裂硅谷
谷歌 Android 安全负责人愤而辞职,公开指责公司「丧失道德指针」。AI 军事化正在撕裂硅谷。

「你在开玩笑吧?」GitHub Copilot 按 Token 计费引爆开发者社区,AI编程工具的免费午餐终结了?
GitHub Copilot 的新定价到底改了什么?2026年6月1日,GitHub Copilot正式切换为flex-billing——基于token消耗的计费模式。TechCrunch报道标题直言:「Are you kidding me? GitHub Copilot's new token-based billing model sparks developer outrage」。开发者社区反应激烈。此前4月GitHub已暂停Copilot Pro和Pro+的新用户注册。新Copilot Max计划按token计费,用户不再享有无限制的AI代码补全。与此对比:Cursor Pro $20/月固定,Claude Code Pro $20/月固定。Copilot Max的token计费在重用量场景下可能远超$20。从4月暂停注册到6月新定价上线,整个过程不到两个月。GitHub沟通策略被广泛批评。AI编程工具的定价正在发生什么变化?AI编程工具的定价体系正在剧烈变动。Copilot从固定月费转向按用量付费,代表了一个行业趋势。AI推理成本并非零——每行AI生成的代码都有GPU算力成本。当用户量达到一定规模,固定月费模型对平台方不可持续。关键问题是成本承担者:开发者(按用量付费)、IDE厂商(固定订阅+补贴AI成本)、还是模型厂商(API降价)?目前三方都在试探边界。Copilot的决策可能加速整个行业向按用量付费的转变。开发者应该如何应对?如果你是个人开发者,固定月费的Cursor或Claude Code仍是性价比最高的选择。如果你是企业团队,需要评估Copilot Max的实际用量成本。建议先在小范围试用一个月,建立用量基线再决定是否全面切换。FAQCopilot Max比Cursor贵多少?取决于用量。轻度使用(日均少于50次补全)可能持平$20。重度使用(日均200+次)可能超过$60/月。固定月费模式会消失吗?短期不会。Cursor和Claude Code仍坚持固定月费。但长期趋势可能是「固定月费+用量上限」的混合模式。应该切换到哪个工具?如果已习惯GitHub生态,先观察一个月实际用量再决定。如果想固定预算,Cursor或Claude Code是更安全的选择。
作者:智盒(aiKit.vip)| 资讯 · 资源 · 工具 · 导航 {
"@context": "https://schema.org",
...

ESMFold2 超越 AlphaFold3:11亿蛋白质结构开源图谱发布,AI for Science 迎来「DeepSeek 时刻」
ESMFold2凭什么超越AlphaFold3?Biohub在5月底发布了ESMFold2,一个完全开源、Apache 2.0商用友好的蛋白质结构预测模型。它生成了11亿蛋白质结构的开源图谱——是AlphaFold数据库(约2亿)的5.5倍。同时收录了68亿蛋白质序列信息。ESMFold2 4.1B参数的MONET模型在GenEval基准上得分0.74,击败了DALL-E 3和12B参数的FLUX.1 Dev。只用对手三分之一参数量就超越,靠的不是算力而是数据质量。团队已用ESMFold2成功设计新型抗体和抗癌蛋白。实验室验证显示高比例设计按预期工作。还意外发现CRISPR微生物防御蛋白与2023年土壤真菌基因编辑蛋白在结构上的相似性——这在AlphaFold中未被发现。为什么这是AI for Science的里程碑?AlphaFold3虽然强大,但代码和模型权重闭源,商业使用受限。ESMFold2以Apache 2.0完全开源,意味着任何实验室、制药公司、科研团队都可以免费商用。这是科学开源精神与商业AI的正面碰撞。ESMFold2还有一个关键突破:能够设计新的蛋白质而不仅仅是预测已知蛋白质结构。抗体和抗癌蛋白的成功设计证明AI不只是"读"生物学,还能"写"生物学。FAQESMFold2可以免费商用吗?是的。Apache 2.0许可,完全开源,无商业限制。ESMFold2与AlphaFold3的差距有多大?在多个蛋白质结构预测基准上ESMFold2超越AlphaFold3。4.1B参数就达到GenEval 0.74。数据质量比模型规模更重要。这对药物研发有什么实际影响?显著降低蛋白质结构预测和设计的门槛。小团队也能使用开源工具设计新型抗体和蛋白质药物。
作者:智盒(aiKit.vip)| 资讯 · 资源 · 工具 · 导航 {
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
...
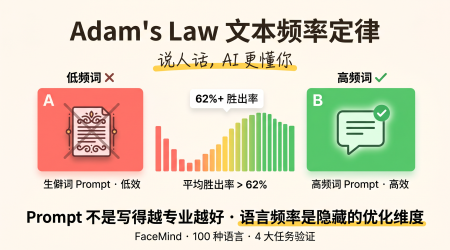
别把 Prompt 写得太「高级」,AI 更需要你「说人话」:Adam's Law 颠覆你的提示词习惯
FaceMind团队用100种语言实验发现:用高频词写Prompt效果比低频词好62%+。Adam's Law告诉我们,AI更吃「说人话」而不是「拽专业词」。附4个改写实例。
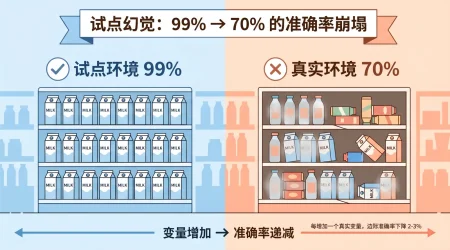
星巴克 AI 翻车实录:一个 99% 准确率的模型,为什么在 11,000 家门店被集体拔线?
试点成功的 AI 系统 ≈ 一个闭卷考满分的实习生进了真实仓库——问题不在模型,在现实世界的方差。拆解星巴克 AI 失败的三个致命陷阱及企业部署必备的三个护栏。

Agent 安全的「宪法时刻」:Anthropic 零信任框架 + OpenAI 私有 MCP + 教皇通谕,同一天三线交汇
5月27日,三件事在同一天发生。它们分属不同领域——安全技术、企业基础设施、宗教伦理——但底层指向同一个问题:当 AI Agent 能自主决策、执行代码、操作生产环境时,安全不再是一个功能需求,而是生存前提。 第一块拼图:Anthropic 的零信任框架 Anthropic 在这一天发布了针对企业部署自主 AI Agent 的安全框架。这不是一篇泛泛而谈的白皮书——它包含了一个分层的三层架构(基础、高级、优化级)和一个八阶段实施流程。 文章的核心判断很直白: 「前沿大语言模型正将漏洞利用周期从数月压缩至数小时。」 换句话说,如果一个漏洞过去给你 90 天修复窗口,现在可能只有几个小时——因为 AI 加速了攻击端的能力,而防守端还在用传统节奏。 框架首次系统性地建模了 Agent 特有的威胁类别:提示注入(prompt injection)、工具投毒(tool poisoning)、记忆投毒(memory poisoning)。这三个威胁在传统 Web 安全或 API 安全的语境中不存在——它们是 Agent 自治能力带来的全新攻击面。 提示注入:攻击者通过精心构造的输入,让 Agent 执行非预期操作。传统 XSS/SQL 注入的攻击对象是应用程序,而提示注入的攻击对象是 LLM 的推理链路。 工具投毒:如果 Agent 可以调用外部 MCP 服务器或 API,攻击者可以通过篡改工具返回的数据来影响 Agent 的决策。这在传统 API 安全中对应的是供应链攻击,但 Agent...

AI 编程 Agent 找到了 PMF——然后定价体系就崩了
一天之内,三件事拼出了一幅完整的图。 Simon Willison 写了一篇博客,标题平淡——《I think Anthropic and OpenAI have found product-market fit》——在 Hacker News 上拿了 638 分。Sam Altman 接受采访时说「AI 对白领冲击不如预期般严重,我很高兴自己当时错了」。Cognition(Devin 的母公司)宣布估值 260 亿美元,年化收入 4.92 亿。 三件事单独看都是新闻,放在一起是一个信号:AI 编程 Agent 找到了 PMF——然后定价规则被重新发明了。 从「无限畅吃」到「按克收费」 Simon Willison 的文章里列出了具体的时间线和数字: 2026 年 4 月前后,Anthropic 和 OpenAI 同时调整了企业套餐定价。此前,两家公司的企业版采用大幅折扣策略——一个固定月费,基本上可以「无限」使用 Claude Code 或 Codex。调整后: Anthropic...

在上班和上进之间,我选择了上香:AI玄学千亿市场深度拆解
全球AI玄学市场突破1800亿美元,18-35岁年轻人68%在算命运势——当AI让算命成本趋近于零,焦虑驱动的千亿赛道正在被技术改写。寺庙经济1000亿、中国AI玄学120亿、复购率38.7%——赛博玄学正在闷声发大财。

Meta-Minus收购案被否决的三大关键信号:AI监管如何重塑产业格局
深入分析Meta收购Manus案被否决的三个信号:AI Agent技术上升到国家安全级别、AI应用价值超越商业范畴、高科技公司外迁时代终结。