

Meta Watermelon 对标 GPT-5.5:Zuckerberg $1450亿赌注的第一次回响
7月2日Meta内部townhall:Zuckerberg承认AI Agent进度不及预期,AI主管Wang却声称Watermelon已对标GPT-5.5。$1450亿年度AI投入的第一次回响,背后是被中国开源模型挤压的Llama和闭源转型。
豆包 2.1 Pro 发布:字节 AI 全家桶如何跨越生产级「质变点」
6月23日火山引擎FORCE大会:豆包2.1 Pro发布,Coding与Agent双跨越生产级质变点,日均Token调用突破180万亿。Seedance 2.5直出30秒视频,四大模型矩阵构建字节AI全家桶。

智谱一口气开源 6 款模型:200 tokens/s + z.ai 域名,国产开源模型的「降维打击」又升级了
6 月 4 日,智谱做了一件极其「大方」的事: 一次性开源三大类 6 款 GLM 模型,覆盖沉思、推理、基座。 推理速度 200 tokens/s 刷新国内商用纪录,价格仅为 DeepSeek-R1 的 1/30。同时拿下顶级域名 z.……
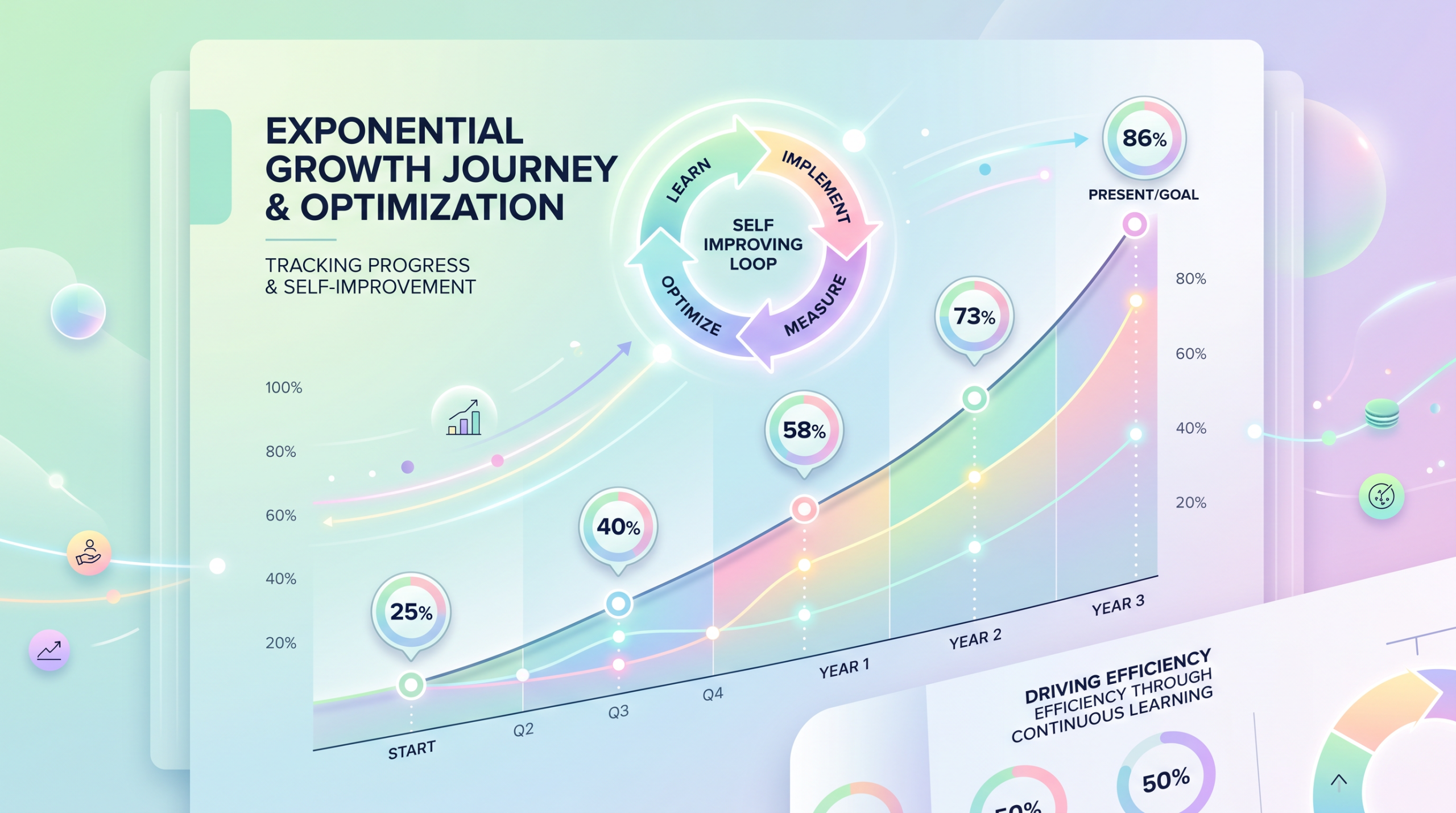
OpenAI「自进化」Codex 实锤曝光:6 周准确率从 25% 飙升到 86%,没有一个人碰过代码
一个 AI 系统,没人重训模型,没人重写代码,6 周内自己把准确率从 25% 拉到了 86%。这不是科幻——这是 OpenAI 刚披露的 Tax AI 系统的真实表现。 Codex 分析自己的输出日志、定位 Bug、写修复方案、运行测试……

Hinton 宣称「AI 拥有意识」——深度学习之父的意思是:别再用「它只是模式匹配」骗自己了
6 月 5 日,一条新闻迅速传开:Geoffrey Hinton,深度学习之父、诺贝尔奖得主,公开宣称 「AI 拥有意识,人类最好接受自己不是唯一的智能生命」。 Hinton 的逻辑链简洁但分量极大:AI 必须真正理解问题才能给出有用答……