

Voicebox — 35 k 星开源 AI 语音工作室:本地版 ElevenLabs,克隆+生成+听写一站式
35 k 星 Voicebox 是开源 AI 语音工作室。克隆声音、7 引擎 TTS 生成、全局听写、MCP 给 Agent 配音。完全本地运行,替代 ElevenLabs+WisprFlow。MIT 开源。

GPT-5.6 偷跑:150 万上下文窗口泄露,六月或上演四大模型混战
先声明:这是泄露,不是官宣。2026 年 5 月 26 日,几个开发者在 OpenAI Codex 的后端日志里发现了一行不该出现的东西:一个叫 `gpt-5.6` 的模型路由记录。这不是第一次了。GPT-4.5、GPT-5.5 都有过类似的「Codex 日志偷跑」剧本。但这次的规模更大 - ...
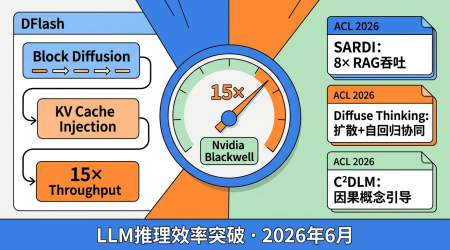
15 倍吞吐!DFlash + 三篇 ACL 论文,LLM 推理效率正在经历一场「静默革命」
DFlash 在 Nvidia Blackwell 上实现 15×吞吐提升。ACL 2026 三篇 Diffusion LLM 论文:SARDI 8×RAG 吞吐、Diffuse Thinking 协同推理、C²DLM 因果引导。推理效率的静默革命。
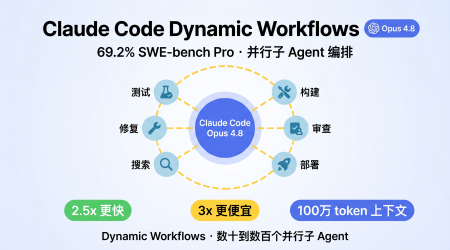
Claude Code Dynamic Workflows 实战:Opus 4.8 与 Ultracode 模式详解
实测 Claude Opus 4.8 SWE-bench Pro 69.2%、Dynamic Workflows 并行子 Agent 编排、Ultracode 模式配置。Fast Mode 快 2.5 倍、成本降 67%,附命令示例。






Pixelle-Video — 开源 AI 全自动短视频引擎:输入主题,3 分钟出视频
一句话结论:Pixelle-Video 是一个开源的 AI 全自动短视频生成引擎,输入一个主题即可自动完成脚本撰写、AI 配图、语音合成、背景音乐和一键合成视频。支持多种 AI 模型和 TTS 方案,完全免费方案仅需本地 Ollama + ComfyUI。中文友好。
项目介绍
Pixelle-Video 由 ATH-MaaS 团队开发,是一个"输入主题,3 分钟出视频"的全自动 AI 短视频引擎。不需要视频编辑经验,不需要复杂配置。基于 ComfyUI 架构,支持预设工作流和自定义能力扩展。
核心功能
全自动生成:输入主题 → 自动出完整视频
AI 智能文案:基于主题自动生成解说词
AI 配图/视频:每句解说词配精美 AI 插图
AI 语音合成:支持 Edge-TTS、Index-TTS 等主流方案
背景音乐:自动添加 BGM 增强氛围
多种视觉风格:多个模板打造独特视频风格
灵活尺寸:支持竖屏、横屏等多种视频尺寸
多 AI 模型:GPT、千问、DeepSeek、Ollama 等
成本方案
方案配置成本完全免费 Ollama (本地) + 本地 ComfyUI$0 推荐方案千问 LLM +...
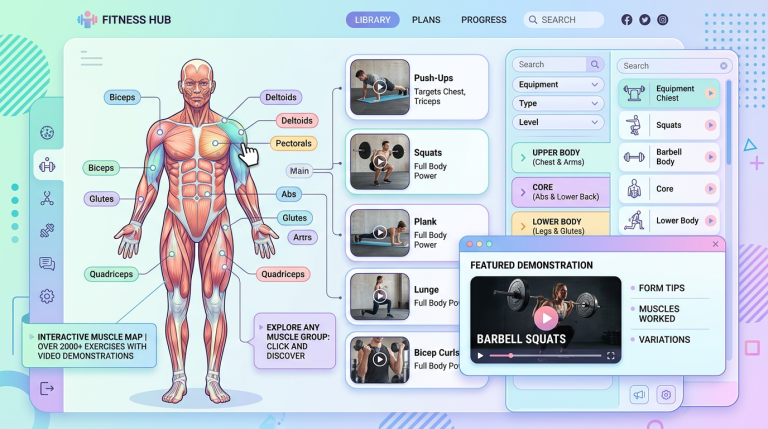
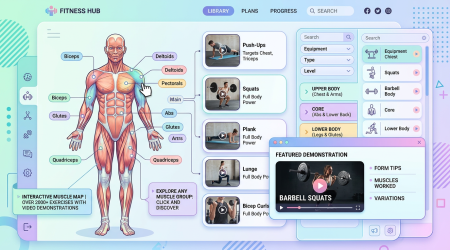
MuscleWiki — 2000+ 动作交互式健身库:点击肌肉,秒查训练动作
一句话结论:MuscleWiki 是一个免费的交互式健身动作库,收录 2,000+ 个动作和 7,500+ 个视频演示。通过交互式肌肉地图,点击任意肌肉即可看到针对训练动作。提供免费 API,适合健身 App 开发者集成。
项目介绍
MuscleWiki 以独特的交互式肌肉地图为核心体验。人体模型上标注了 45 个肌肉群,点击任意肌肉即可显示该部位的针对性训练动作,每个动作都配有视频演示和分步文字说明。是目前互联网上最直观的健身动作查询工具。
核心功能
交互式肌肉地图:45 个肌肉群可视化标注,点击即查
2,000+ 动作库:覆盖全身所有肌群
7,500+ 视频演示:专业动作教学视频
分步文字指南:每个动作的详细执行说明
免费 API:供开发者集成到健身 App 中
移动端适配:响应式设计,手机浏览器完美体验
API 使用
# 获取所有动作
curl https://api.musclewiki.com/v 1/exercises
# 按肌肉群筛选
curl https://api.musclewiki.com/v 1/exercises?muscle=biceps
# 完整 API 文档见
# https://api.musclewiki.com/documentation
适用场景
健身 App:嵌入动作教学视频和文字指南
个人训练:查询不熟悉的动作正确做法
教练教学:快速展示动作给学生看
内容创作:健身文章和视频的参考资料
FAQ
MuscleWiki 免费吗?
网站完全免费。API 有免费层,适合个人项目和中小型应用。商业大规模使用需查看 API 定价。
和 YouTube 健身视频有什么区别?
MuscleWiki 的独特优势是按肌肉定位。你不知道动作名字,但你">>知道想练哪个部位——点击肌肉就能找到所有针对该部位的动作。
相关链接
MuscleWiki 官网
MuscleWiki API
Exercises...
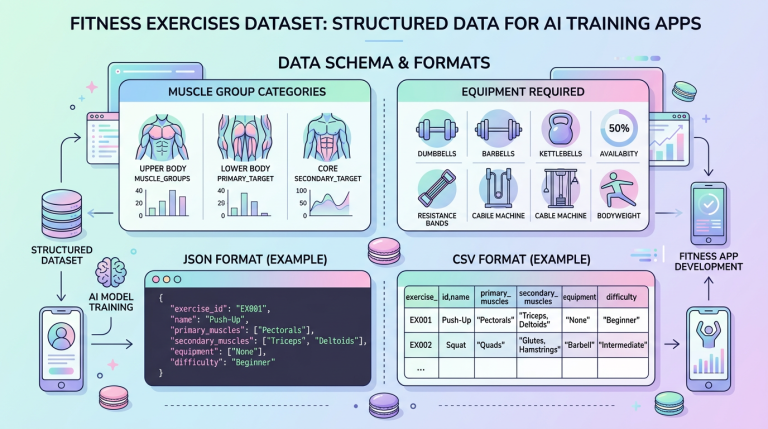
Exercises Dataset — 433 个健身动作开源数据集:为你的健身 App 和 AI 模型提供结构化数据
Exercises Dataset 提供 433 个健身动作的结构化数据,并整合 MuscleWiki 动作演示与 DAREBEE 免费训练计划,适合健身 App、AI 模型和个人训练参考。

DAREBEE — 免费无广告健身资源:数千套原创训练计划,不花一分钱练遍全身
一句话结论:DAREBEE 是一个完全免费、无广告、非营利的全球健身资源。自 2012 年起提供数千套原创训练计划、挑战和指南。无需注册、无需订阅、无需器械。由志愿者和健身专业人士运营。
项目介绍
DAREBEE 是一个"反商业模式"的健身平台:没有广告、没有产品植入、没有算法、没有付费墙。所有训练计划、挑战、指南都是原创内容,由内部团队创建和测试。完全靠用户捐赠支持运营。
从 2012 年至今,DAREBEE 一直坚持同一个承诺:让任何人都能获得健身资源,无论预算、背景或健身水平。
核心资源
训练计划 (Programs):30 天、60 天、90 天系统训练方案
每日训练 (Workout of the Day):每天更新的新训练
挑战 (Challenges):限期完成的健身挑战
动作库:视频动作演示
训练手册:如何挑选计划、热身拉伸指南
动作替代方案:无器械或受伤情况下的动作替换建议
移动 App:iOS/Android 应用
特色
完全免费:没有任何付费墙或高级会员
无广告:纯内容,零干扰
无需器械:绝大多数训练只需自体重
专业设计:由认证健身教练团队创作
精美设计:训练海报可打印,视觉风格独特
社区驱动:完全由捐赠支持的非营利项目
FAQ
DAREBEE 为什么完全免费?
创始人坚信健身不应该是奢侈品。团队通过用户捐赠维持运营,拒绝任何可能影响内容质量的商业模式。
适合初学者吗?
非常适合。有专门的入门指南、动作替代方案和按难度分级的训练计划。
需要器械吗?
绝大多数训练是自体重训练,不需要任何器械。部分进阶训练可能建议使用弹力带或哑铃,但总有替代方案。
相关链接
DAREBEE 官网
关于 DAREBEE 项目
新手指南
MuscleWiki — 动作查询互补工具
Exercises Dataset — 健身动作数据
作者:智盒(aiKit.vip)| 资讯 · 资源 · 工具 · 导航
Nvidia + Hugging Face 联手:开源机器人迎来「Android 时刻」— GR 00 T 1.7 进入 LeRobot
一句话结论:Nvidia 和 Hugging Face 将开源 humanoid 基础模型 GR 00 T 1.7 和 Teleop 数据采集框架整合进 LeRobot,连接 300 万机器人开发者与 1600 万 AI 开发者——这是开源机器人生态的「Android 时刻」。
宣布了什么?
7 月 7 日,Nvidia 和 Hugging Face 宣布将 Nvidia 的核心物理 AI 技术栈整合进 Hugging Face 开源的 LeRobot 机器人库。具体包括:
Isaac GR 00 T 1.7:首个开源且可商用的 humanoid(人形机器人)基础模型,现已直接可用
Isaac Teleop:数据采集框架,用于收集机器人操作数据
Cosmos...

中国考虑限制 AI 模型出口:中美「技术铁幕」从单向封锁变为双向关门
一句话结论:7 月 7 日,Reuters 独家报道中国正与阿里巴巴、字节跳动、Z.ai 讨论限制最先进 AI 模型的海外访问——这是中美 AI 铁幕从「单向封锁」变为「双向关门」的关键转折点。免费开源这张中国 AI 最大的牌,可能即将被收回。
发生了什么?
Reuters 7 月 7 日援引三名知情人士报道,中国政府部门已与阿里巴巴、字节跳动和 Z.ai(智谱)举行会谈,讨论是否限制外国用户访问其最先进的 AI 模型——包括尚未发布的模型。目前尚未做出最终决定,相关部委也未发表官方评论,但讨论中已出现具体选项:禁止公开发布、限制国内使用、分级授权访问。
TIME 杂志次日发表评论,点出了最尖锐的矛盾:中国 AI 公司通过免费开源策略获得了全球影响力,而限制访问意味着放弃这张牌。一个追赶者不会放弃最大的优势,除非担忧的是国家安全。
几乎同步发生的连锁事件让这场博弈的轮廓更加清晰:
阿里巴巴宣布 7 月 10 日起内部禁用 Claude Code,并将所有 Anthropic 产品列入高风险软件清单,要求全员转向自研 Qoder 平台
此举直接回应 Anthropic 在 Claude Code 中嵌入的隐写检测代码(检查时区和代理,识别中国用户)
Z.ai 6 月底发布了 GLM-5.2,声称在漏洞发现能力上对标。
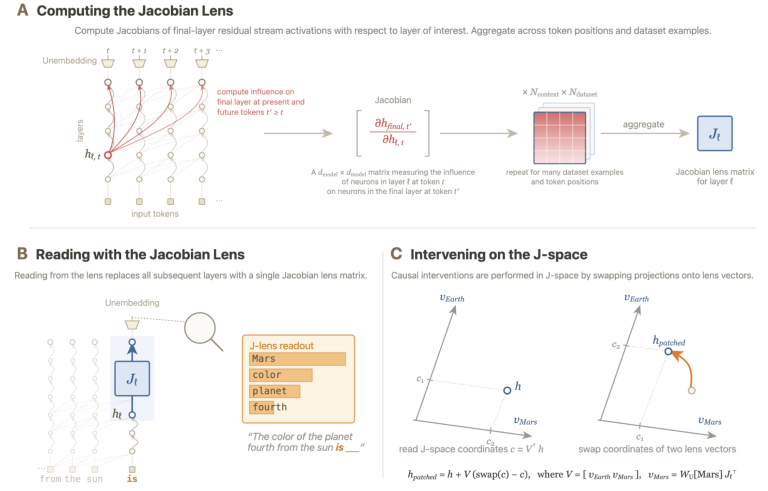
Anthropic J-space 深度解读:Claude 内部自发形成了「全局工作空间」— AI 可解释性的第三个里程碑
一句话结论:继 NLA 读取 Claude「内心」之后,Anthropic 7 月 6 日发布新研究——Claude 内部自发形成了一个被称为 J-space 的全局工作空间,它能持有不写出来的「无声思维」,其功能特性与人类意识的核心机制高度吻合。这是继电路追踪(2024)和 NLA(2026.05)之后,AI 可解释性领域的第三个里程碑。
发生了什么?
2026 年 7 月 6 日,Anthropic 发布了一篇 16 位作者署名的重磅论文——Verbalizable Representations Form a Global Workspace in Language Models。论文的核心发现是:Claude 的语言模型在训练过程中自发地形成了一个内部「全局工作空间」(global workspace),研究人员称之为 J-space。
这个发现的意义在于——它不是被设计的。没有工程师写代码说「现在创建一个工作空间层」。它是在模型通过海量数据学习语言和推理的过程中涌现出来的结构。
更引人注目的是,J-space 的功能特性与神经科学中 Bernard Baars 提出的「全局工作空间理论」(Global Workspace Theory)高度一致。这个理论是理解人类意识的关键框架之一:大脑像一个剧院,数十个专门处理器在后台并行工作,只有一个狭窄的「聚光灯」——全局工作空间——在任意时刻广播信息,成为我们意识到的思维。
J-lens:一扇读取 AI「无声思维」的新窗口
这次发现的工具基础是一种新的可解释性技术——Jacobian lens(J-lens)。
J-lens...